Project 2 - 서울시 범죄 현황 데이터 분석 (1)
Project 02. Analysis Seoul Crime
프로젝트 개요
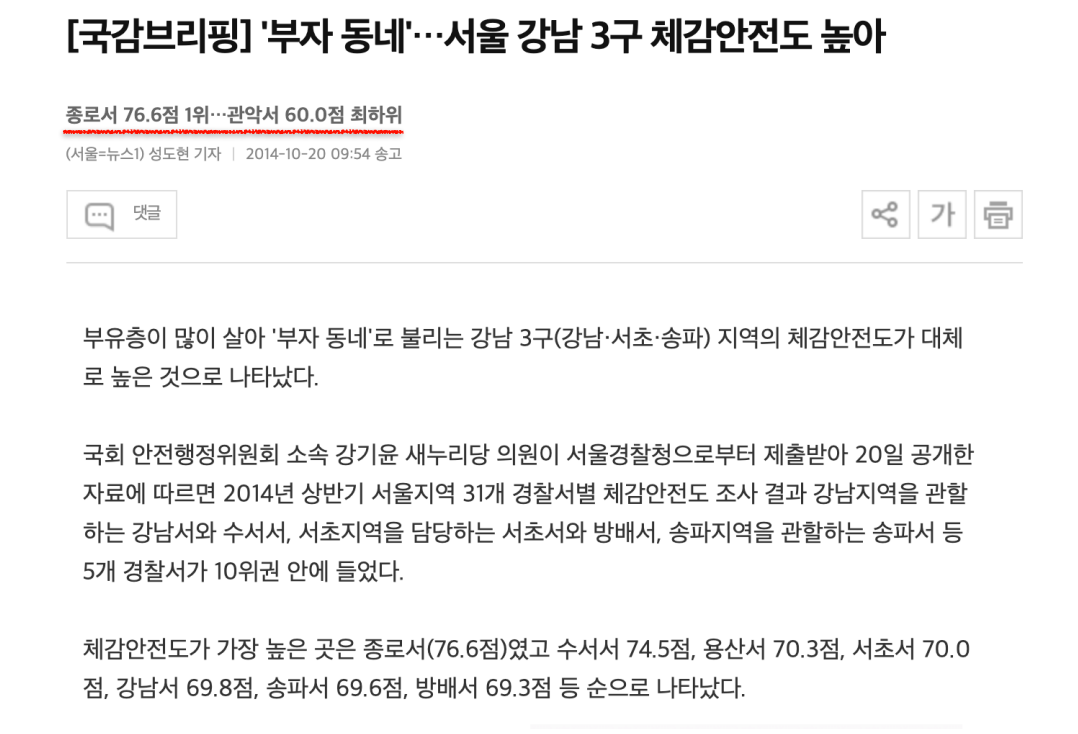
- 실제 강남3구가 범죄로부터 안전한지 데이터로 확인
데이터 개요
import numpy as np
import pandas as pd
# 데이터 읽기
crime_raw_data = pd.read_csv('../data/02. crime_in_Seoul.csv', thousands=",", encoding="euc-kr")
# thousands 숫자값을 문자로 인식할 수 있기 때문에 설정
crime_raw_data.head()
| 구분 | 죄종 | 발생검거 | 건수 | |
|---|---|---|---|---|
| 0 | 중부 | 살인 | 발생 | 2.0 |
| 1 | 중부 | 살인 | 검거 | 2.0 |
| 2 | 중부 | 강도 | 발생 | 3.0 |
| 3 | 중부 | 강도 | 검거 | 3.0 |
| 4 | 중부 | 강간 | 발생 | 141.0 |
crime_raw_data.info()
=>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 65534 entries, 0 to 65533
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 구분 310 non-null object
1 죄종 310 non-null object
2 발생검거 310 non-null object
3 건수 310 non-null float64
dtypes: float64(1), object(3)
memory usage: 2.0+ MB
- info(): 데이터의 개요 확인하기
-
RangeIndex가 65534인데, 데이터가 310개뿐인 것 확인
```python crime_raw_data[‘죄종’].unique()
=>
array([‘살인’, ‘강도’, ‘강간’, ‘절도’, ‘폭력’, nan], dtype=object)
- 특정 컬럼에서 unique 조사
- nan 값 발견
---
```python
crime_raw_data[crime_raw_data['죄종'].isnull()].head()
| |구분|죄종|발생검거|건수| |::|:-:|:–:|—–|:–:| |310|NaN|NaN|NaN|NaN| |311|NaN|NaN|NaN|NaN| |312|NaN|NaN|NaN|NaN| |313|NaN|NaN|NaN|NaN| |314|NaN|NaN|NaN|NaN|
crime_raw_data = crime_raw_data[crime_raw_data['죄종'].notnull()]
crime_raw_data.info()
=>
<class 'pandas.core.frame.DataFrame'>
Int64Index: 310 entries, 0 to 309
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 구분 310 non-null object
1 죄종 310 non-null object
2 발생검거 310 non-null object
3 건수 310 non-null float64
dtypes: float64(1), object(3)
memory usage: 12.1+ KB
crime_raw_data.head()
| |구분|죄종|발생검거|건수| |::|:-:|:–:|—–|:–:| |0| 중부| 살인| 발생| 2.0| |1| 중부| 살인| 검거| 2.0| |2| 중부| 강도| 발생| 3.0| |3| 중부| 강도| 검거| 3.0| |4| 중부| 강간| 발생| 141.0|
crime_raw_data.tail()
| |구분|죄종|발생검거|건수| |::|:-:|:–:|—–|:–:| |305| 수서| 강간| 검거| 144.0| |306| 수서| 절도| 발생| 1149.0| |307| 수서| 절도| 검거| 789.0| |308| 수서| 폭력| 발생| 1666.0| |309| 수서| 폭력| 검거| 1431.0|
Pandas pivot table
- index, columns, values, aggfunc
df = pd.read_excel("../data/02. sales-funnel.xlsx")
df.head()
| Account | Name | Rep | Manager | Product | Quantity | Price | Status | |
|---|---|---|---|---|---|---|---|---|
| 0 | 714466 | Trantow-Barrows | Craig Booker | Debra Henley | CPU | 1 | 30000 | presented |
| 1 | 714466 | Trantow-Barrows | Craig Booker | Debra Henley | Software | 1 | 10000 | presented |
| 2 | 714466 | Trantow-Barrows | Craig Booker | Debra Henley | Maintenance | 2 | 5000 | pending |
| 3 | 737550 | Fritsch, Russel and Anderson | Craig Booker | Debra Henley | CPU | 1 | 35000 | declined |
| 4 | 146832 | Kiehn-Spinka | Daniel Hilton | Debra Henley | CPU | 2 | 65000 | won |
index 설정
Name 컬럼을 인덱스로 설정
df.pivot_table(index="Name") # pd.pivot_table(df, index="Name")
| Account | Price | Quantity | |
|---|---|---|---|
| Name | |||
| Barton LLC | 740150 | 35000 | 1.000000 |
| Fritsch, Russel and Anderson | 737550 | 35000 | 1.000000 |
| Herman LLC | 141962 | 65000 | 2.000000 |
| Jerde-Hilpert | 412290 | 5000 | 2.000000 |
| Kassulke, Ondricka and Metz | 307599 | 7000 | 3.000000 |
| Keeling LLC | 688981 | 100000 | 5.000000 |
| Kiehn-Spinka | 146832 | 65000 | 2.000000 |
| Koepp Ltd | 729833 | 35000 | 2.000000 |
| Kulas Inc | 218895 | 25000 | 1.500000 |
| Purdy-Kunde | 163416 | 30000 | 1.000000 |
| Stokes LLC | 239344 | 7500 | 1.000000 |
| Trantow-Barrows | 714466 | 15000 | 1.333333 |
멀티 인덱스 설정
df.pivot_table(index=["Name", "Rep", "Manager"])
| Account | Price | Quantity | |||
|---|---|---|---|---|---|
| Name | Rep | Manager | |||
| Barton LLC | John Smith | Debra Henley | 740150 | 35000 | 1.000000 |
| Fritsch, Russel and Anderson | Craig Booker | Debra Henley | 737550 | 35000 | 1.000000 |
| Herman LLC | Cedric Moss | Fred Anderson | 141962 | 65000 | 2.000000 |
| Jerde-Hilpert | John Smith | Debra Henley | 412290 | 5000 | 2.000000 |
| Kassulke, Ondricka and Metz | Wendy Yule | Fred Anderson | 307599 | 7000 | 3.000000 |
| Keeling LLC | Wendy Yule | Fred Anderson | 688981 | 100000 | 5.000000 |
| Kiehn-Spinka | Daniel Hilton | Debra Henley | 146832 | 65000 | 2.000000 |
| Koepp Ltd | Wendy Yule | Fred Anderson | 729833 | 35000 | 2.000000 |
| Kulas Inc | Daniel Hilton | Debra Henley | 218895 | 25000 | 1.500000 |
| Purdy-Kunde | Cedric Moss | Fred Anderson | 163416 | 30000 | 1.000000 |
| Stokes LLC | Cedric Moss | Fred Anderson | 239344 | 7500 | 1.000000 |
| Trantow-Barrows | Craig Booker | Debra Henley | 714466 | 15000 | 1.333333 |
df.pivot_table(index=["Manager", "Rep"])
| Account | Price | Quantity | ||
|---|---|---|---|---|
| Manager | Rep | |||
| Debra Henley | Craig Booker | 720237.0 | 20000.000000 | 1.250000 |
| Daniel Hilton | 194874.0 | 38333.333333 | 1.666667 | |
| John Smith | 576220.0 | 20000.000000 | 1.500000 | |
| Fred Anderson | Cedric Moss | 196016.5 | 27500.000000 | 1.250000 |
| Wendy Yule | 614061.5 | 44250.000000 | 3.000000 |
values 설정
df.pivot_table(index=["Manager", "Rep"], values="Price")
| Price | ||
|---|---|---|
| Manager | Rep | |
| Debra Henley | Craig Booker | 20000.000000 |
| Daniel Hilton | 38333.333333 | |
| John Smith | 20000.000000 | |
| Fred Anderson | Cedric Moss | 27500.000000 |
| Wendy Yule | 44250.000000 |
Price 컬럼 sum 연산 적용
df.pivot_table(index=["Manager", "Rep"], values="Price", aggfunc=np.sum)
| Price | ||
|---|---|---|
| Manager | Rep | |
| Debra Henley | Craig Booker | 80000 |
| Daniel Hilton | 115000 | |
| John Smith | 40000 | |
| Fred Anderson | Cedric Moss | 110000 |
| Wendy Yule | 177000 |
df.pivot_table(index=["Manager", "Rep"], values="Price", aggfunc=[np.sum, len])
| sum | len | ||
|---|---|---|---|
| Price | Price | ||
| Manager | Rep | ||
| Debra Henley | Craig Booker | 80000 | 4 |
| Daniel Hilton | 115000 | 3 | |
| John Smith | 40000 | 2 | |
| Fred Anderson | Cedric Moss | 110000 | 4 |
| Wendy Yule | 177000 | 4 |
columns 설정
Product를 컬럼으로 지정
df.pivot_table(index=["Manager", "Rep"], values="Price", columns="Product", aggfunc=np.sum)
| Product | CPU | Maintenance | Monitor | Software | |
|---|---|---|---|---|---|
| Manager | Rep | ||||
| Debra Henley | Craig Booker | 65000.0 | 5000.0 | NaN | 10000.0 |
| Daniel Hilton | 105000.0 | NaN | NaN | 10000.0 | |
| John Smith | 35000.0 | 5000.0 | NaN | NaN | |
| Fred Anderson | Cedric Moss | 95000.0 | 5000.0 | NaN | 10000.0 |
| Wendy Yule | 165000.0 | 7000.0 | 5000.0 | NaN |
Nan 값 설정 : fill_value
df.pivot_table(index=["Manager", "Rep"], values="Price", columns="Product", aggfunc=np.sum, fill_value=0)
| Product | CPU | Maintenance | Monitor | Software | |
|---|---|---|---|---|---|
| Manager | Rep | ||||
| Debra Henley | Craig Booker | 65000 | 5000 | 0 | 10000 |
| Daniel Hilton | 105000 | 0 | 0 | 10000 | |
| John Smith | 35000 | 5000 | 0 | 0 | |
| Fred Anderson | Cedric Moss | 95000 | 5000 | 0 | 10000 |
| Wendy Yule | 165000 | 7000 | 5000 | 0 |
2개 이상 index, values 설정
df.pivot_table(index=["Manager", "Rep", "Product"], values=["Price", "Quantity"], aggfunc=np.sum, fill_value=0)
| Price | Quantity | |||
|---|---|---|---|---|
| Manager | Rep | Product | ||
| Debra Henley | Craig Booker | CPU | 65000 | 2 |
| Maintenance | 5000 | 2 | ||
| Software | 10000 | 1 | ||
| Daniel Hilton | CPU | 105000 | 4 | |
| Software | 10000 | 1 | ||
| John Smith | CPU | 35000 | 1 | |
| Maintenance | 5000 | 2 | ||
| Fred Anderson | Cedric Moss | CPU | 95000 | 3 |
| Maintenance | 5000 | 1 | ||
| Software | 10000 | 1 | ||
| Wendy Yule | CPU | 165000 | 7 | |
| Maintenance | 7000 | 3 | ||
| Monitor | 5000 | 2 |
aggfunc 2개 이상 설정
df.pivot_table(
index=["Manager", "Rep", "Product"],
values=["Price", "Quantity"],
aggfunc=[np.sum, np.mean], fill_value=0,
margins=True # 총계(All) 추가
)
| sum | mean | |||||
|---|---|---|---|---|---|---|
| Price | Quantity | Price | Quantity | |||
| Manager | Rep | Product | ||||
| Debra Henley | Craig Booker | CPU | 65000 | 2 | 32500.000000 | 1.000000 |
| Maintenance | 5000 | 2 | 5000.000000 | 2.000000 | ||
| Software | 10000 | 1 | 10000.000000 | 1.000000 | ||
| Daniel Hilton | CPU | 105000 | 4 | 52500.000000 | 2.000000 | |
| Software | 10000 | 1 | 10000.000000 | 1.000000 | ||
| John Smith | CPU | 35000 | 1 | 35000.000000 | 1.000000 | |
| Maintenance | 5000 | 2 | 5000.000000 | 2.000000 | ||
| Fred Anderson | Cedric Moss | CPU | 95000 | 3 | 47500.000000 | 1.500000 |
| Maintenance | 5000 | 1 | 5000.000000 | 1.000000 | ||
| Software | 10000 | 1 | 10000.000000 | 1.000000 | ||
| Wendy Yule | CPU | 165000 | 7 | 82500.000000 | 3.500000 | |
| Maintenance | 7000 | 3 | 7000.000000 | 3.000000 | ||
| Monitor | 5000 | 2 | 5000.000000 | 2.000000 | ||
| All | 522000 | 30 | 30705.882353 | 1.764706 | ||
서울시 범죄 현황 데이터 정리
데이터 정리
crime_station = crime_raw_data.pivot_table(
crime_raw_data,
index="구분",
columns=["죄종", "발생검거"],
aggfunc=[np.sum]
)
crime_station.head()
| sum | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 건수 | ||||||||||
| 죄종 | 강간 | 강도 | 살인 | 절도 | 폭력 | |||||
| 발생검거 | 검거 | 발생 | 검거 | 발생 | 검거 | 발생 | 검거 | 발생 | 검거 | 발생 |
| 구분 | ||||||||||
| 강남 | 269.0 | 339.0 | 26.0 | 24.0 | 3.0 | 3.0 | 1129.0 | 2438.0 | 2096.0 | 2336.0 |
| 강동 | 152.0 | 160.0 | 13.0 | 14.0 | 5.0 | 4.0 | 902.0 | 1754.0 | 2201.0 | 2530.0 |
| 강북 | 159.0 | 217.0 | 4.0 | 5.0 | 6.0 | 7.0 | 672.0 | 1222.0 | 2482.0 | 2778.0 |
| 강서 | 239.0 | 275.0 | 10.0 | 10.0 | 10.0 | 9.0 | 1070.0 | 1952.0 | 2768.0 | 3204.0 |
| 관악 | 264.0 | 322.0 | 10.0 | 12.0 | 7.0 | 6.0 | 937.0 | 2103.0 | 2707.0 | 3235.0 |
- 경찰서 이름을 index하도록 정리
- default가 평균(mean)
- column이 multi로 잡힌 모습
다중 컬럼에서 특정 컬럼 제거
crime_station.columns # Multiindex
=>
MultiIndex([('sum', '건수', '강간', '검거'),
('sum', '건수', '강간', '발생'),
('sum', '건수', '강도', '검거'),
('sum', '건수', '강도', '발생'),
('sum', '건수', '살인', '검거'),
('sum', '건수', '살인', '발생'),
('sum', '건수', '절도', '검거'),
('sum', '건수', '절도', '발생'),
('sum', '건수', '폭력', '검거'),
('sum', '건수', '폭력', '발생')],
names=[None, None, '죄종', '발생검거'])
crime_station["sum", "건수", "강도", "검거"][:5]
=>
구분
강남 26.0
강동 13.0
강북 4.0
강서 10.0
관악 10.0
Name: (sum, 건수, 강도, 검거), dtype: float64
crime_station.columns = crime_station.columns.droplevel([0, 1]) #다중 컬럼에서 특정 컬럼 제거
crime_station.columns
=>
MultiIndex([('강간', '검거'),
('강간', '발생'),
('강도', '검거'),
('강도', '발생'),
('살인', '검거'),
('살인', '발생'),
('절도', '검거'),
('절도', '발생'),
('폭력', '검거'),
('폭력', '발생')],
names=['죄종', '발생검거'])
crime_station.head()
| 죄종 | 강간 | 강도 | 살인 | 절도 | 폭력 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| 발생검거 | 검거 | 발생 | 검거 | 발생 | 검거 | 발생 | 검거 | 발생 | 검거 | 발생 |
| 구분 | ||||||||||
| 강남 | 269.0 | 339.0 | 26.0 | 24.0 | 3.0 | 3.0 | 1129.0 | 2438.0 | 2096.0 | 2336.0 |
| 강동 | 152.0 | 160.0 | 13.0 | 14.0 | 5.0 | 4.0 | 902.0 | 1754.0 | 2201.0 | 2530.0 |
| 강북 | 159.0 | 217.0 | 4.0 | 5.0 | 6.0 | 7.0 | 672.0 | 1222.0 | 2482.0 | 2778.0 |
| 강서 | 239.0 | 275.0 | 10.0 | 10.0 | 10.0 | 9.0 | 1070.0 | 1952.0 | 2768.0 | 3204.0 |
| 관악 | 264.0 | 322.0 | 10.0 | 12.0 | 7.0 | 6.0 | 937.0 | 2103.0 | 2707.0 | 3235.0 |
crime_station.index
=>
Index(['강남', '강동', '강북', '강서', '관악', '광진', '구로', '금천', '남대문', '노원', '도봉',
'동대문', '동작', '마포', '방배', '서대문', '서부', '서초', '성동', '성북', '송파', '수서',
'양천', '영등포', '용산', '은평', '종로', '종암', '중랑', '중부', '혜화'],
dtype='object', name='구분')
→ 경찰서 이름으로 해당 구 이름을 알아내야 함
Google Maps API 설치 및 테스트
import googlemaps
gmaps_key = "~"
gmaps = googlemaps.Client(key=gmaps_key)
gmaps.geocode("서울영등포경찰서", language="ko")
=>
[{'address_components': [{'long_name': '608',
'short_name': '608',
'types': ['premise']},
{'long_name': '국회대로',
'short_name': '국회대로',
'types': ['political', 'sublocality', 'sublocality_level_4']},
{'long_name': '영등포구',
'short_name': '영등포구',
'types': ['political', 'sublocality', 'sublocality_level_1']},
{'long_name': '서울특별시',
'short_name': '서울특별시',
'types': ['administrative_area_level_1', 'political']},
{'long_name': '대한민국',
'short_name': 'KR',
'types': ['country', 'political']},
{'long_name': '150-043',
'short_name': '150-043',
'types': ['postal_code']}],
'formatted_address': '대한민국 서울특별시 영등포구 국회대로 608',
'geometry': {'location': {'lat': 37.5260441, 'lng': 126.9008091},
'location_type': 'ROOFTOP',
'viewport': {'northeast': {'lat': 37.5273930802915,
'lng': 126.9021580802915},
'southwest': {'lat': 37.5246951197085, 'lng': 126.8994601197085}}},
'partial_match': True,
'place_id': 'ChIJ1TimJLaffDURptXOs0Tj6sY',
'plus_code': {'compound_code': 'GWG2+C8 대한민국 서울특별시',
'global_code': '8Q98GWG2+C8'},
'types': ['establishment', 'point_of_interest', 'police']}]
출처
서울시 관서별 5대 범죄 현황, https://www.data.go.kr/data/15054738/fileData.do?recommendDataYn=Y