Project 4 - 시카고 맛집 데이터 분석
시카고 맛집 데이터 분석
1. 개요
- https://www.chicagomag.com/chicago-magazine/november-2012/best-sandwiches-chicago/
- chicago magazine the 50 best sandwiches
목표
50개 페이지에서 각 가게의 정보 가져오기
- 가게이름
- 대표메뉴
- 대표메뉴의 가격
- 가게주소
2. 메인페이지
from urllib.request import Request, urlopen
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
import ssl
context = ssl._create_unverified_context()
url_base = "https://www.chicagomag.com/"
url_sub = "chicago-magazine/november-2012/best-sandwiches-chicago/"
url = url_base + url_sub
ua = UserAgent()
req = Request(url, headers={"User-Agent": ua.ie})
html = urlopen(req, context=context)
soup = BeautifulSoup(html, "html.parser")
print(soup.prettify())
=>
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="utf-8"/>
<meta content="IE=edge" http-equiv="X-UA-Compatible">
<link href="https://gmpg.org/xfn/11" rel="profile"/>
<script src="https://cmp.osano.com/16A1AnRt2Fn8i1unj/f15ebf08-7008-40fe-
...
</script>
</body>
</html>
soup.find_all("div", class_="sammy"), len(soup.find_all("div", class_="sammy"))
# soup.select(".sammy"), len(soup.select(".sammy"))
=>
([<div class="sammy" style="position: relative;">
<div class="sammyRank">1</div>
<div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/"><b>BLT</b><br/>
Old Oak Tap<br/>
<em>Read more</em> </a></div>
</div>,
<div class="sammy" style="position: relative;">
<div class="sammyRank">2</div>
<div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-
...
<div class="sammyListing"><a href="https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Phoebes-Bakery-The-Gatsby/"><b>The Gatsby</b><br/>
Phoebe’s Bakery<br/>
<em>Read more</em> </a></div>
</div>],
50)
tmp_one = soup.find_all("div", "sammy")[0]
type(tmp_one)
=>
bs4.element.Tag
tmp_one.find(class_="sammyRank").get_text()
# tmp_one.select_one(".sammyRank").text
=>
'1'
tmp_one.find("div", {"class":"sammyListing"}).text
# tmp_one.select_one(".sammyListing").get_text()
=>
'BLT\nOld Oak Tap\nRead more '
tmp_one.find("a")["href"]
# tmp_one.select_one("a").get("href")
=>
'/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/'
import re
tmp_string = tmp_one.find(class_="sammyListing").get_text()
re.split(("\n|\r\n"), tmp_string)
=>
['BLT', 'Old Oak Tap', 'Read more ']
print(re.split(("\n|\r\n"), tmp_string)[0]) # menu
print(re.split(("\n|\r\n"), tmp_string)[1]) # cafe
=>
BLT
Old Oak Tap
DataFrame
from urllib.parse import urljoin
url_base = "http://www.chicagomag.com"
# 필요한 내용을 담을 빈 리스트
# 리스트로 하나씩 컬럼을 만들고, DataFrame으로 합칠 예정
rank = []
main_menu = []
cafe_name = []
url_add = []
list_soup = soup.find_all("div", "sammy") # soup.select(".sammy")
for item in list_soup:
rank.append(item.find(class_="sammyRank").get_text())
tmp_string = item.find(class_="sammyListing").get_text()
main_menu.append(re.split(("\n|\r\n"), tmp_string)[0])
cafe_name.append(re.split(("\n|\r\n"), tmp_string)[1])
url_add.append(urljoin(url_base, item.find("a")["href"]))
import pandas as pd
data = {
"Rank": rank,
"Menu": main_menu,
"Cafe": cafe_name,
"URL": url_add,
}
df = pd.DataFrame(data)
df.tail(2)
| Rank | Menu | Cafe | URL | |
|---|---|---|---|---|
| 48 | 49 | Le Végétarien | Toni Patisserie | https://www.chicagomag.com/Chicago-Magazine/No... |
| 49 | 50 | The Gatsby | Phoebe’s Bakery | https://www.chicagomag.com/Chicago-Magazine/No... |
컬럼 순서 변경
df = pd.DataFrame(data, columns=["Rank", "Cafe", "Menu", "URL"])
df.tail()
| Rank | Cafe | Menu | URL | |
|---|---|---|---|---|
| 45 | 46 | Chickpea | Kufta | https://www.chicagomag.com/Chicago-Magazine/No... |
| 46 | 47 | The Goddess and Grocer | Debbie’s Egg Salad | https://www.chicagomag.com/Chicago-Magazine/No... |
| 47 | 48 | Zenwich | Beef Curry | https://www.chicagomag.com/Chicago-Magazine/No... |
| 48 | 49 | Toni Patisserie | Le Végétarien | https://www.chicagomag.com/Chicago-Magazine/No... |
| 49 | 50 | Phoebe’s Bakery | The Gatsby | https://www.chicagomag.com/Chicago-Magazine/No... |
데이터 저장
df.to_csv(
"../data/03. best_sandwiches_list_chicago.csv", sep=",", encoding="utf-8"
)
3. 하위페이지
requirements
import pandas as pd
from urllib.request import urlopen, Request
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
df = pd.read_csv("../data/03. best_sandwiches_list_chicago.csv", index_col=0)
df.tail()
| Rank | Cafe | Menu | URL | |
|---|---|---|---|---|
| 45 | 46 | Chickpea | Kufta | https://www.chicagomag.com/Chicago-Magazine/No... |
| 46 | 47 | The Goddess and Grocer | Debbie’s Egg Salad | https://www.chicagomag.com/Chicago-Magazine/No... |
| 47 | 48 | Zenwich | Beef Curry | https://www.chicagomag.com/Chicago-Magazine/No... |
| 48 | 49 | Toni Patisserie | Le Végétarien | https://www.chicagomag.com/Chicago-Magazine/No... |
| 49 | 50 | Phoebe’s Bakery | The Gatsby | https://www.chicagomag.com/Chicago-Magazine/No... |
df["URL"][0]
=>
'http://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/'
req = Request(df["URL"][0], headers={"user-agent":ua.ie})
html = urlopen(req, context=context).read()
soup_tmp = BeautifulSoup(html, "html.parser")
soup_tmp.find("p", "addy") # soup_find.select_one(".addy")
=>
<p class="addy">
<em>$10. 2109 W. Chicago Ave., 773-772-0406, <a href="http://www.theoldoaktap.com/">theoldoaktap.com</a></em></p>
regular expression
price_tmp = soup_tmp.find("p", "addy").text
price_tmp
=>
'\n$10. 2109 W. Chicago Ave., 773-772-0406, theoldoaktap.com'
import re
re.split(".,", price_tmp)
=>
['\n$10. 2109 W. Chicago Ave', ' 773-772-040', ' theoldoaktap.com']
price_tmp = re.split(".,", price_tmp)[0]
price_tmp
=>
'\n$10. 2109 W. Chicago Ave'
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price_tmp[len(tmp) + 2:]
=>
'2109 W. Chicago Ave'
가격, 주소 추가
from tqdm import tqdm
price = []
address = []
for idx, row in tqdm(df.iterrows()):
req = Request(row["URL"], headers={"user-agent":ua.ie})
html = urlopen(req, context=context).read()
soup_tmp = BeautifulSoup(html, "lxml")
gettings = soup_tmp.find("p", "addy").get_text()
price_tmp = re.split(".,", gettings)[0]
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp) + 2:])
df["Price"] = price
df["Address"] = address
df = df.loc[:, ["Rank", "Cafe", "Menu", "Price", "Address"]]
df.set_index("Rank", inplace=True)
df.head()
| Cafe | Menu | Price | Address | |
|---|---|---|---|---|
| Rank | ||||
| 1 | Old Oak Tap | BLT | $10. | 2109 W. Chicago Ave |
| 2 | Au Cheval | Fried Bologna | $9. | 800 W. Randolph St |
| 3 | Xoco | Woodland Mushroom | $9.50 | 445 N. Clark St |
| 4 | Al’s Deli | Roast Beef | $9.40 | 914 Noyes St |
| 5 | Publican Quality Meats | PB&L | $10. | 825 W. Fulton Mkt |
지도 시각화
requirements
import folium
import pandas as pd
import numpy as np
import googlemaps
from tqdm import tqdm
gmaps_key = ""
gmaps = googlemaps.Client(key=gmaps_key)
lat = []
lng = []
for idx, row in tqdm(df.iterrows()):
if not row["Address"] == "Multiple location":
target_name = row["Address"] + ", " + "Chicago"
# print(target_name)
gmaps_output = gmaps.geocode(target_name)
location_output = gmaps_output[0].get("geometry")
lat.append(location_output["location"]["lat"])
lng.append(location_output["location"]["lng"])
# location_output = gmaps_output[0]
else:
lat.append(np.nan)
lng.append(np.nan)
df.tail()
| Cafe | Menu | Price | Address | |
|---|---|---|---|---|
| Rank | ||||
| 46 | Chickpea | Kufta | $8. | 2018 W. Chicago Ave |
| 47 | The Goddess and Grocer | Debbie’s Egg Salad | $6.50 | 25 E. Delaware Pl |
| 48 | Zenwich | Beef Curry | $7.50 | 416 N. York St |
| 49 | Toni Patisserie | Le Végétarien | $8.75 | 65 E. Washington St |
| 50 | Phoebe’s Bakery | The Gatsby | $6.85 | 3351 N. Broadwa |
df["lat"] = lat
df["lng"] = lng
df.tail()
| Cafe | Menu | Price | Address | lat | lng | |
|---|---|---|---|---|---|---|
| Rank | ||||||
| 46 | Chickpea | Kufta | $8. | 2018 W. Chicago Ave | 41.896113 | -87.677857 |
| 47 | The Goddess and Grocer | Debbie’s Egg Salad | $6.50 | 25 E. Delaware Pl | 41.898979 | -87.627393 |
| 48 | Zenwich | Beef Curry | $7.50 | 416 N. York St | 41.910583 | -87.940488 |
| 49 | Toni Patisserie | Le Végétarien | $8.75 | 65 E. Washington St | 41.883106 | -87.625438 |
| 50 | Phoebe’s Bakery | The Gatsby | $6.85 | 3351 N. Broadwa | 41.943163 | -87.644507 |
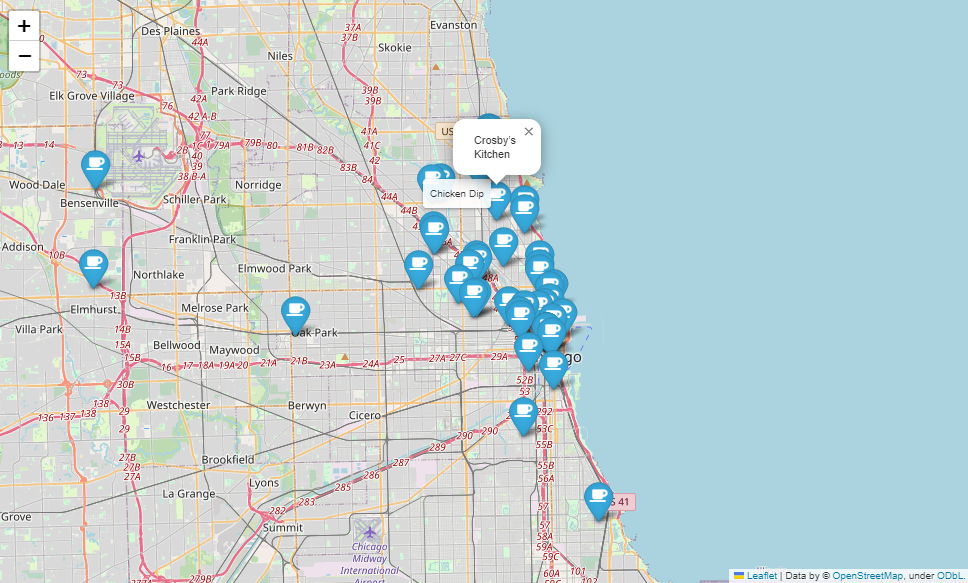
mapping = folium.Map(location=[41.8781136, -87.6297982], zoom_start=11)
for idx, row in df.iterrows():
if not row["Address"] == "Multiple location":
folium.Marker(
location=[row["lat"], row["lng"]],
popup=row["Cafe"],
tooltip=row["Menu"],
icon=folium.Icon(
icon="coffee",
prefix="fa"
)
).add_to(mapping)
mapping