Project 1 - 서울시 CCTV 현황 데이터 분석 (2)
두 데이터 합치기
merge를 이용한 데이터 병합

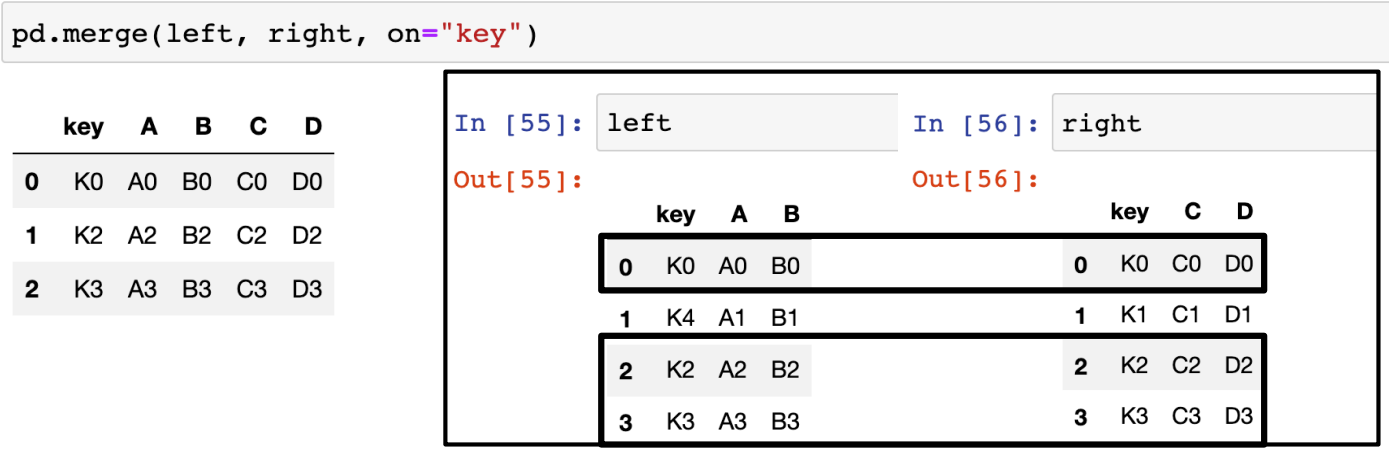
- key 컬럼을 기준으로 병합
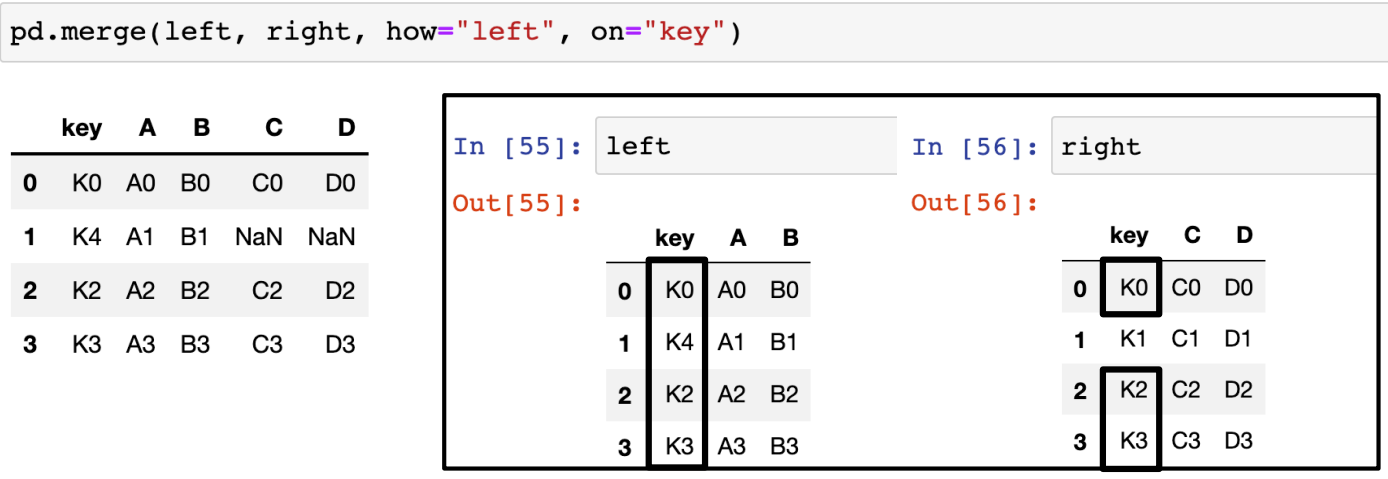
- left에 키를 기준으로 right 병합

- key를 기준으로 합집합 병합

- key 컬럼에서 교집합 병합
데이터 병합 및 정리
데이터 병합
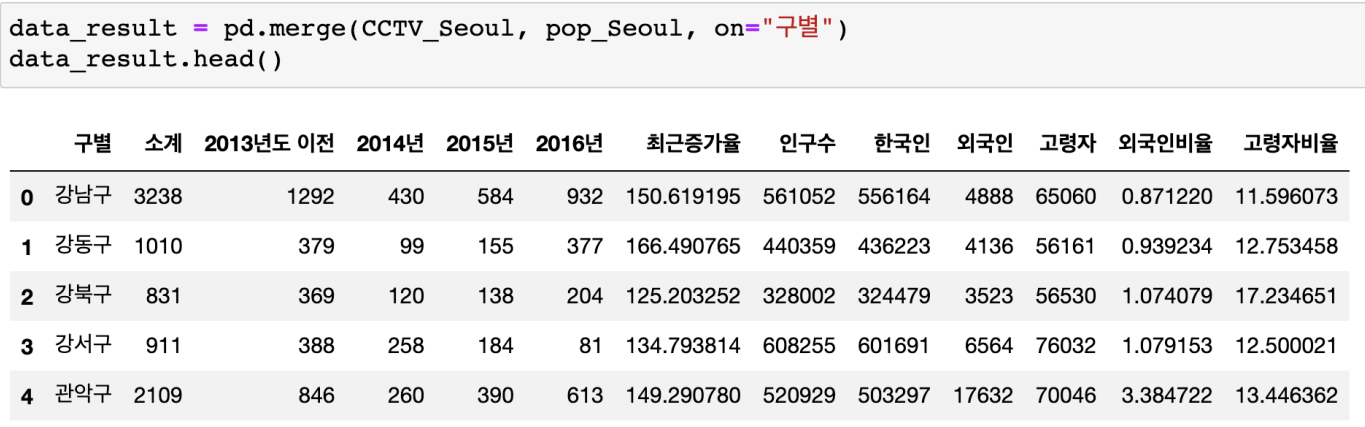
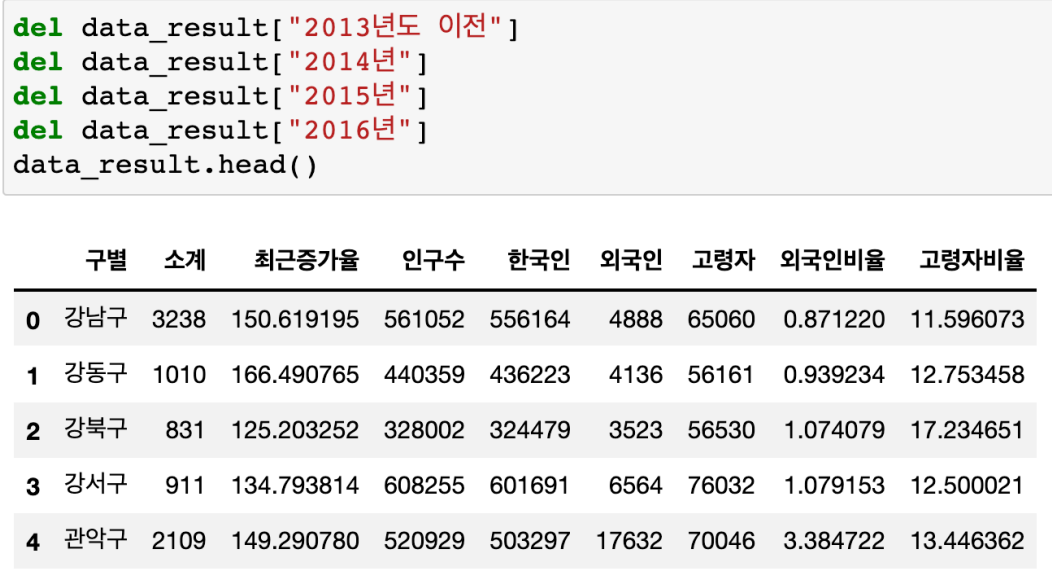
필요 없는 컬럼 제거
인덱스 재지정
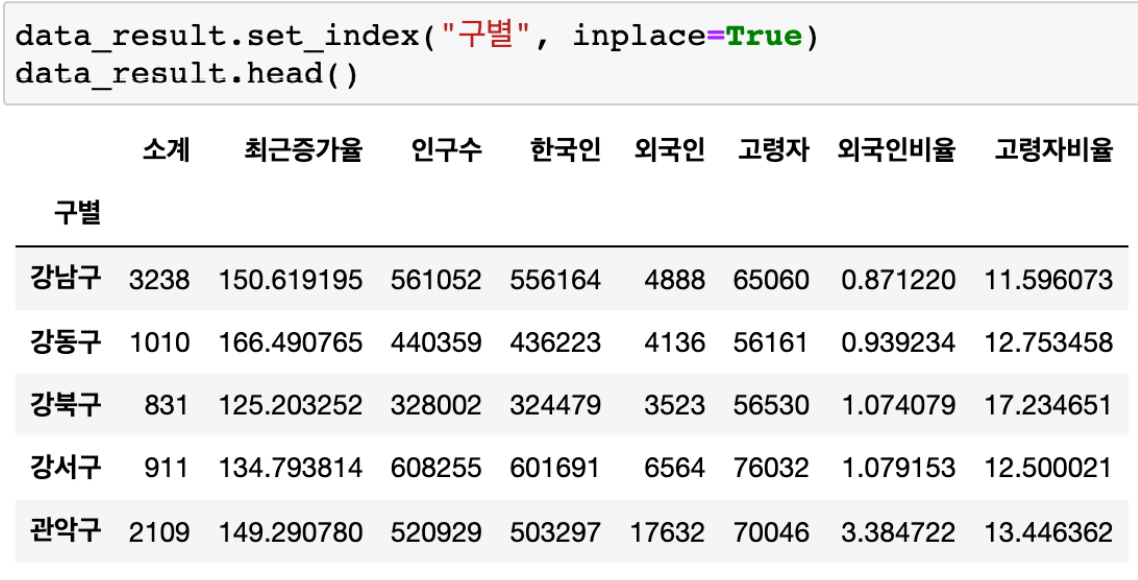
- 재지정 명령어 : set_index
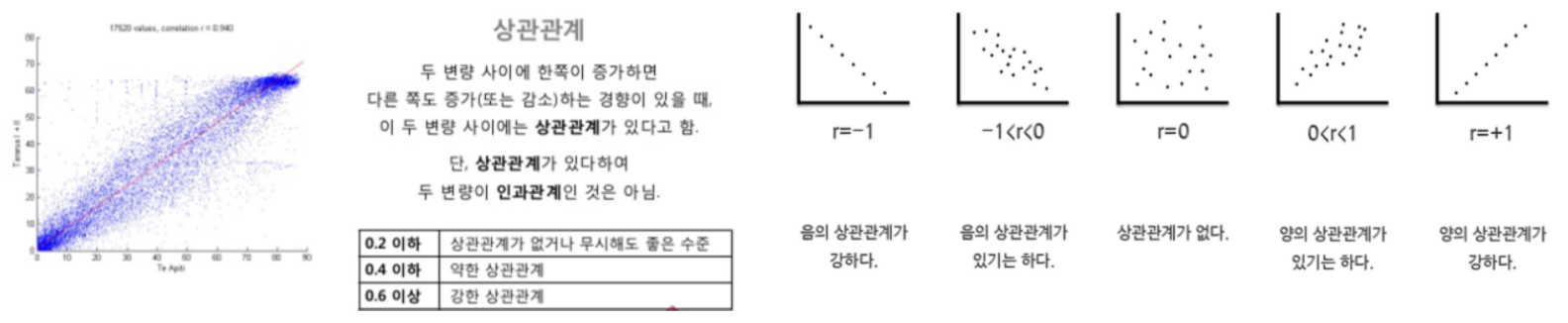
상관관계(Correlation)
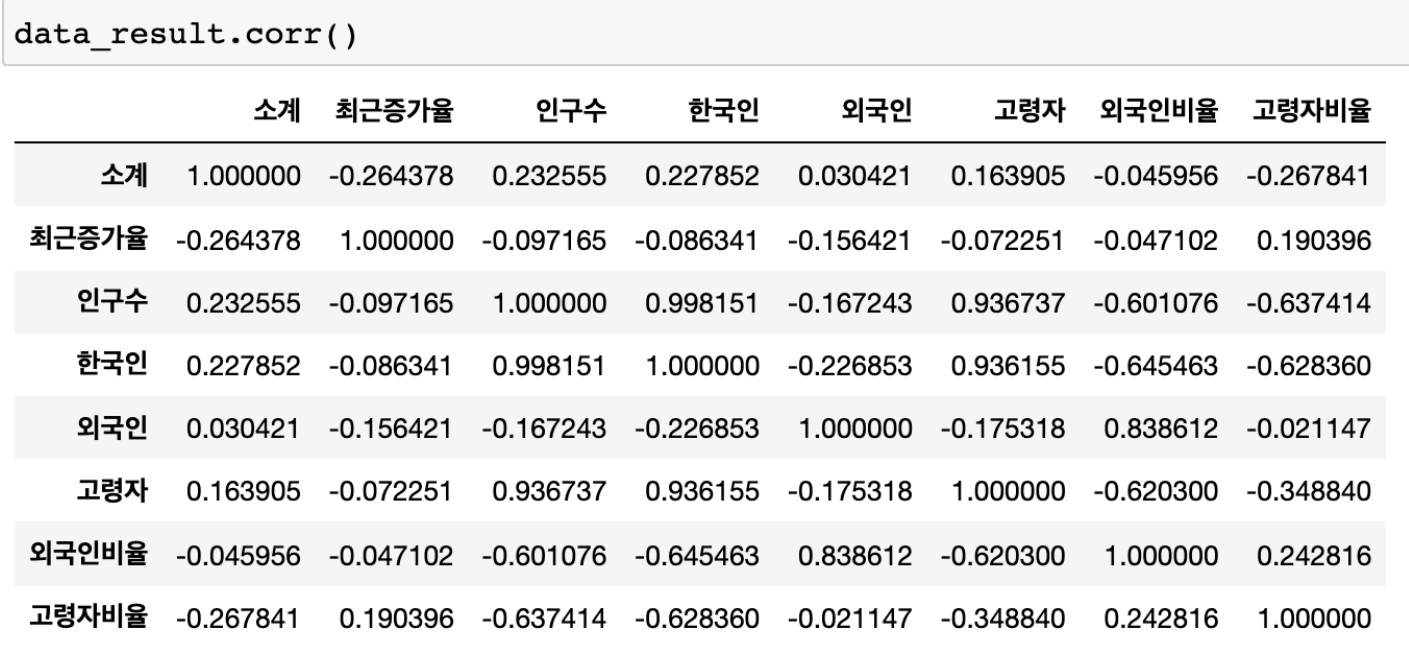
corr()
- 데이터의 관계를 찾을 때, 최소한의 근거가 있어야 해당 데이터를 비교하는 의미가 존재
- 상관계수를 조사해서 0.2 이상의 데이터를 비교하는 것은 유의미
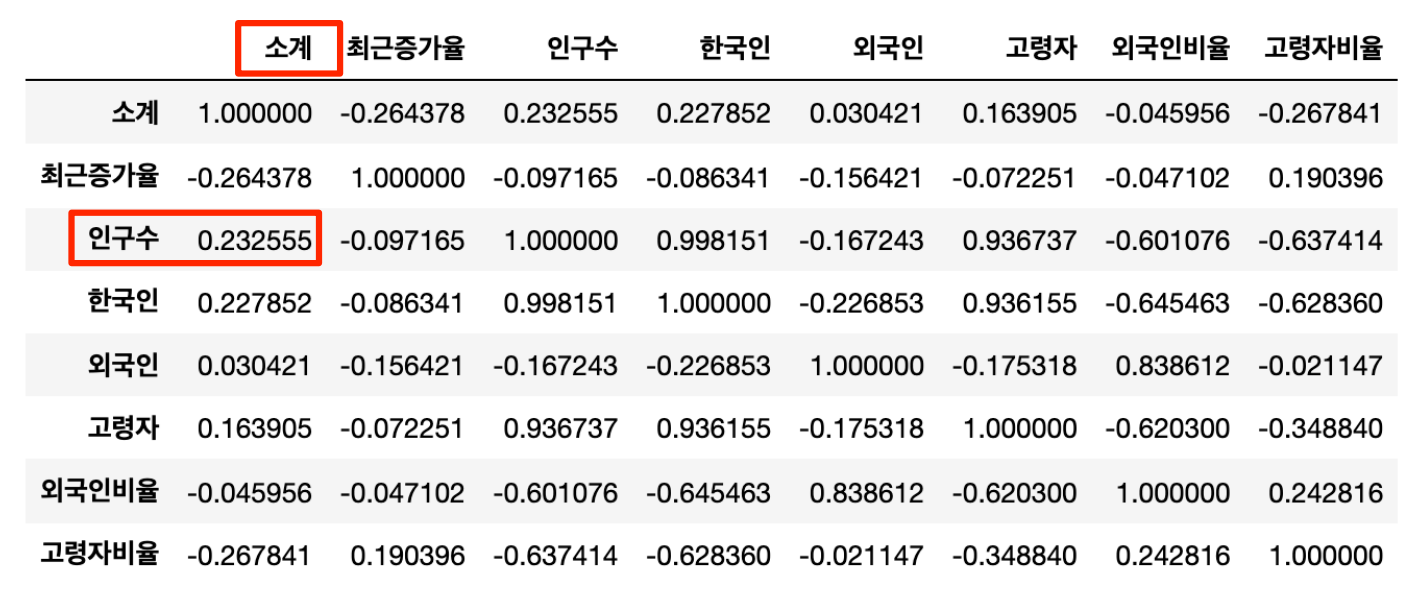
- CCTV 전체 수(소계)와 가장 상관관계가 있는 데이터 → 인구수
- ∴ 구별 인구대비 CCTV 현황을 분석해서 상대적으로 CCTV가 적거나 많은 구를 찾는 것이 의미를 가짐
CCTV 비율
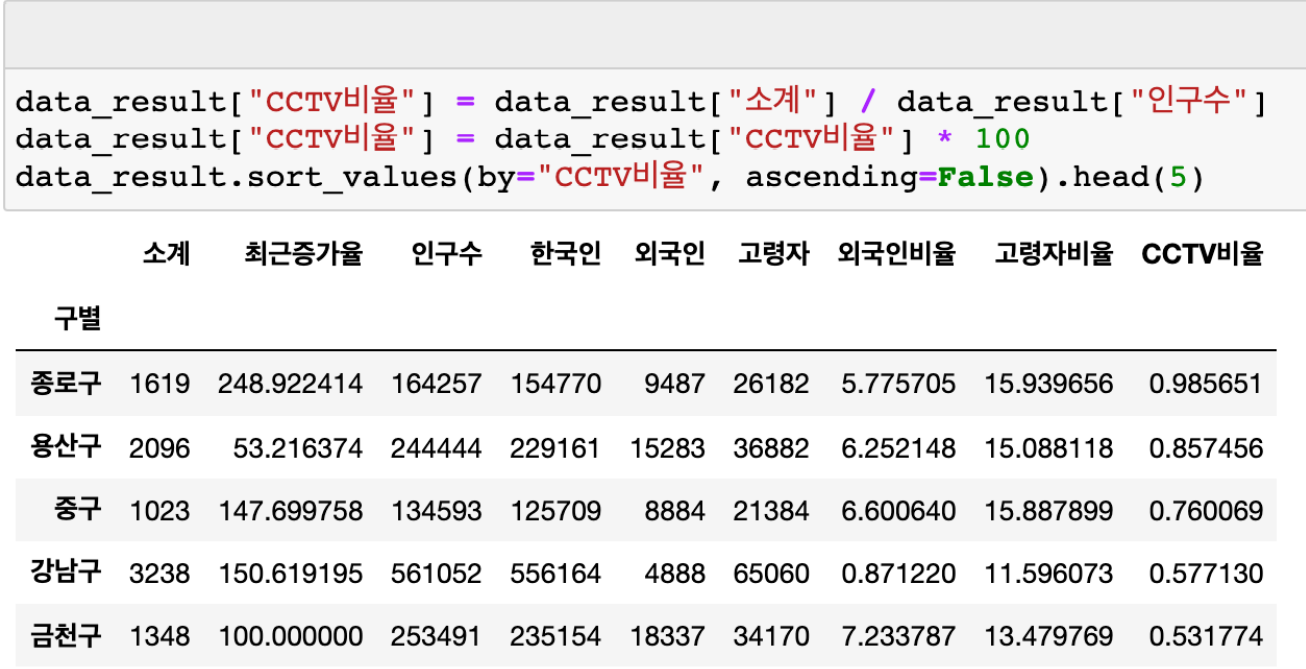
- 인구대비 CCTV 비율이 높은 구
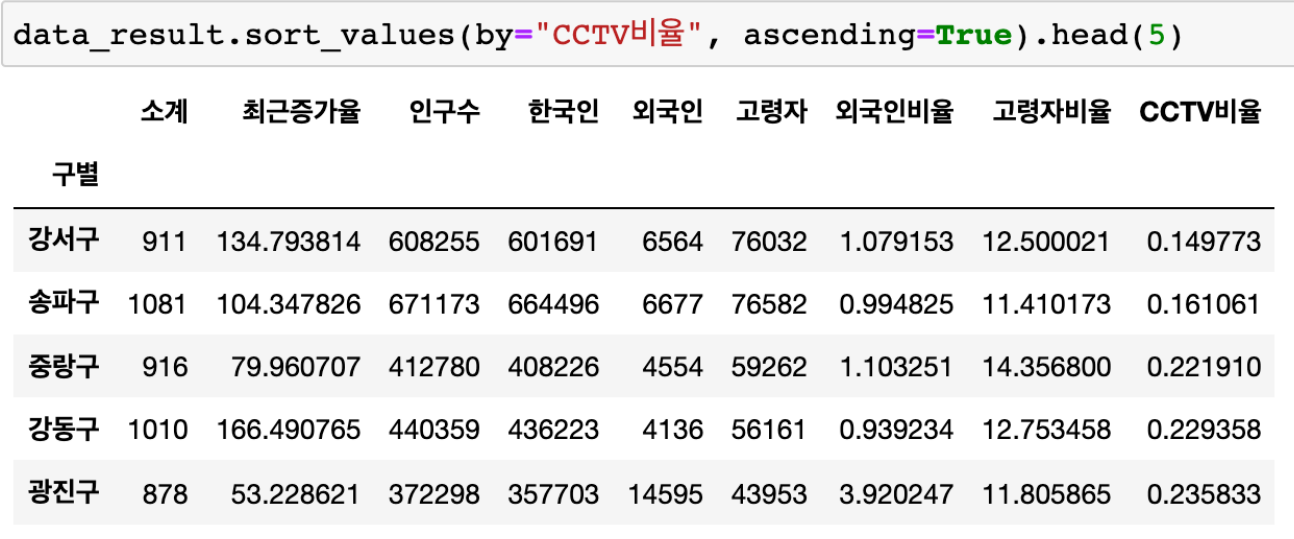
- 인구대비 CCTV 비율이 낮은 구
Matplotlib
- 파이썬 대표 시각화 도구
- Jupyter Notebook의 경우 matplotlib의 결과가 out session에 나타나는 것이 유리하므로 %matplotlib inline 옵션 사용
matplotlib 호출

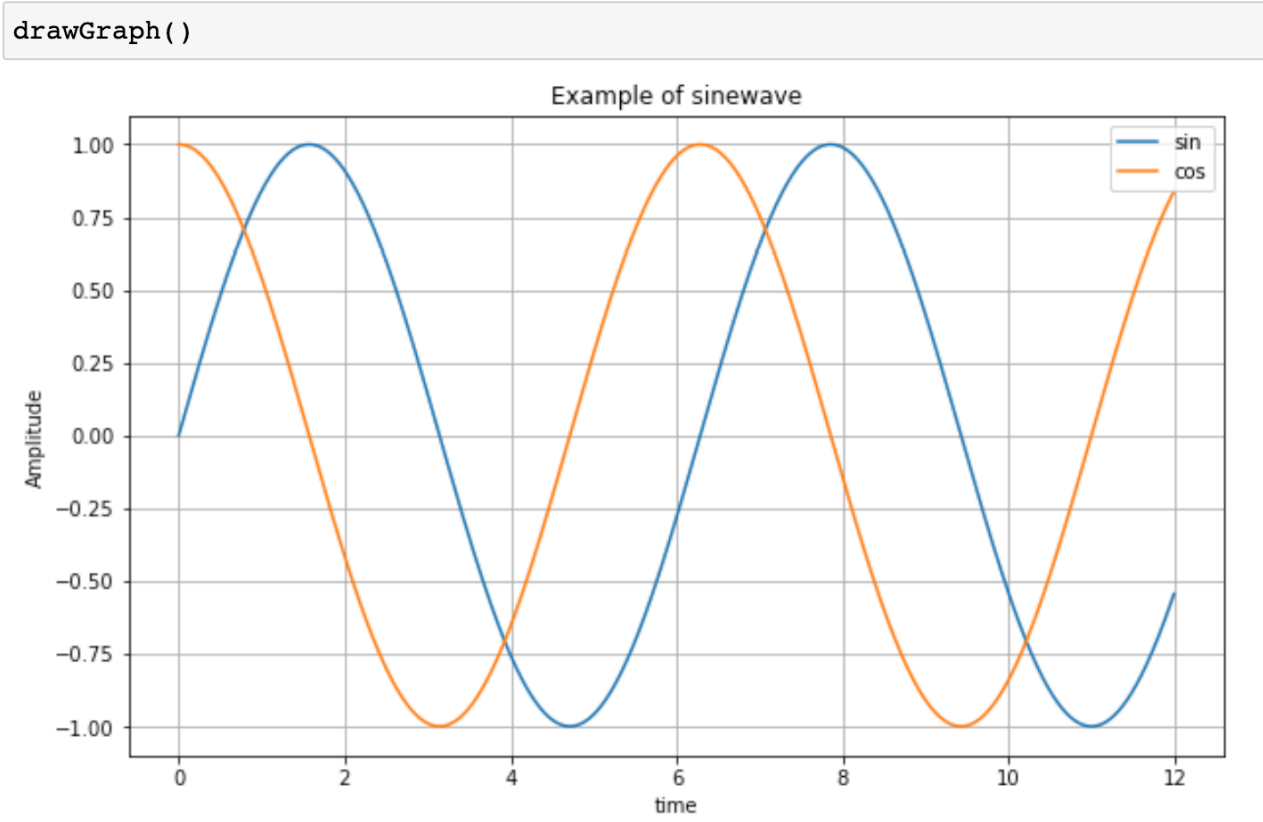
삼각함수 그리기


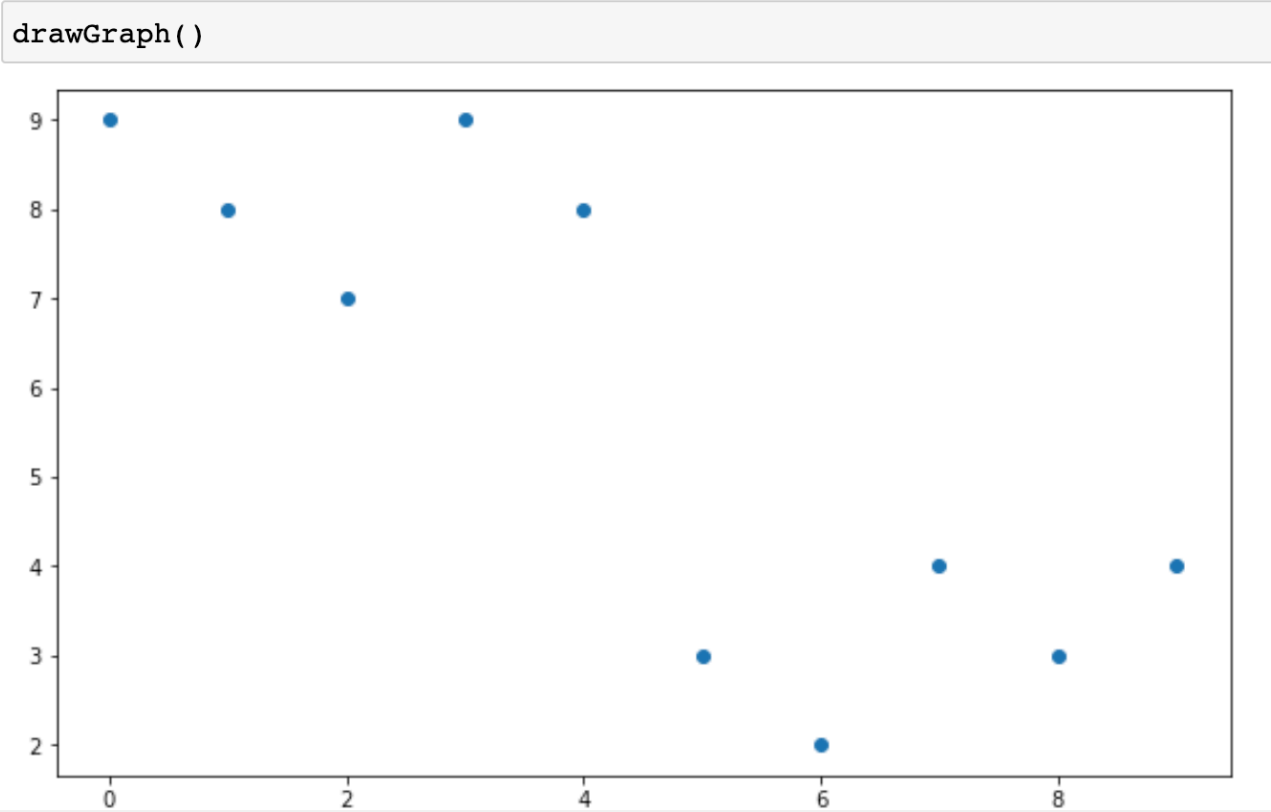
scatter()


데이터 시각화

- 한글 폰트 적용 및 마이너스 기호 적용 (window: “malgun gothic”)

- Pandas DataFrame은 데이터 변수에서 plot() 사용 가능
- 데이터(컬럼)가 많은 경우 정렬한 후 그리는 것이 효과적
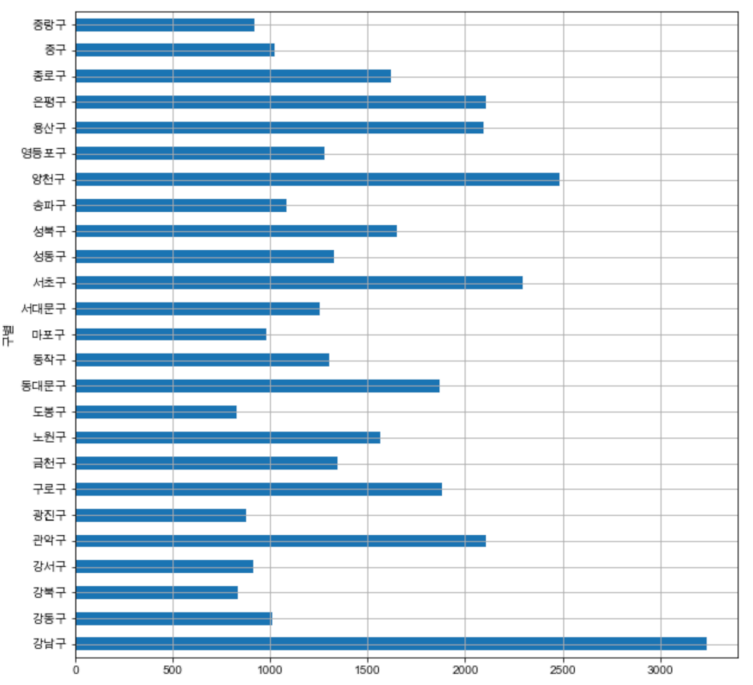


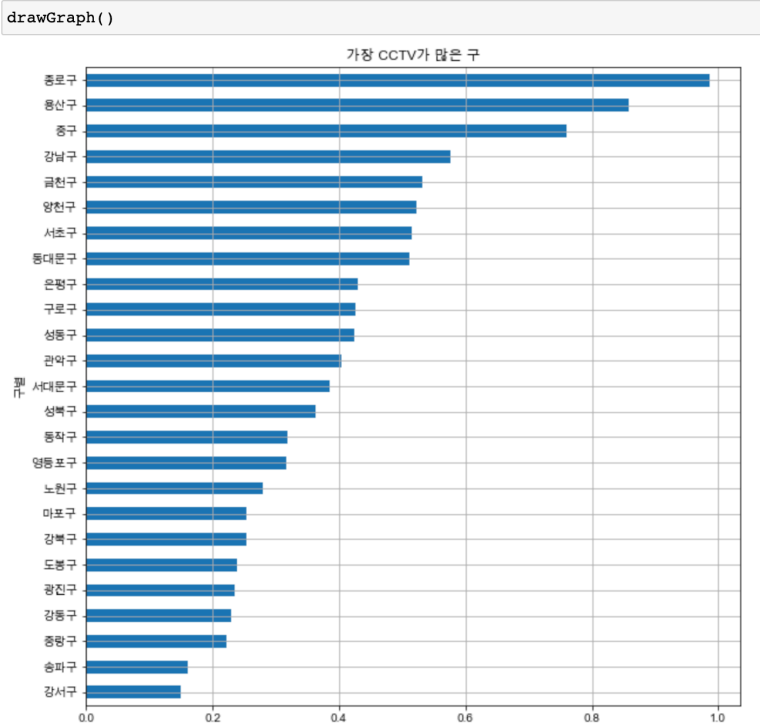
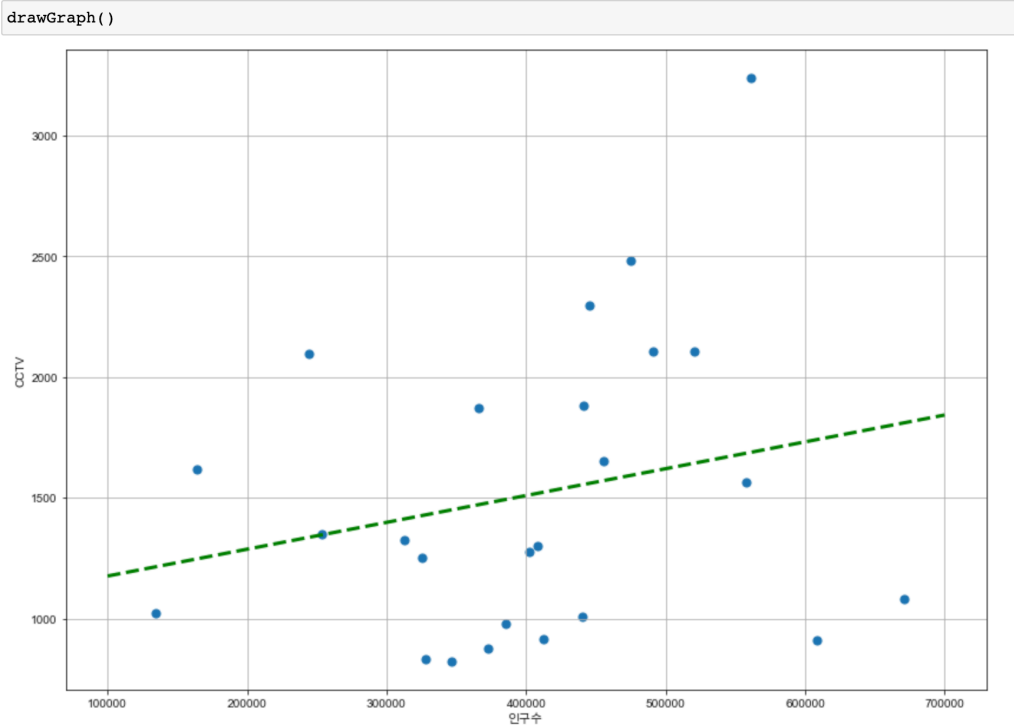
경향 파악
- 단순 CCTV 많은 구 : 강남, 양천, 서초, 관악, 은평, 용산
- CCTV 비율 높은 구 : 종로, 용산, 중구
- 전체 경향과 함께 보지 않으면 제대로 이해시키기 어려움

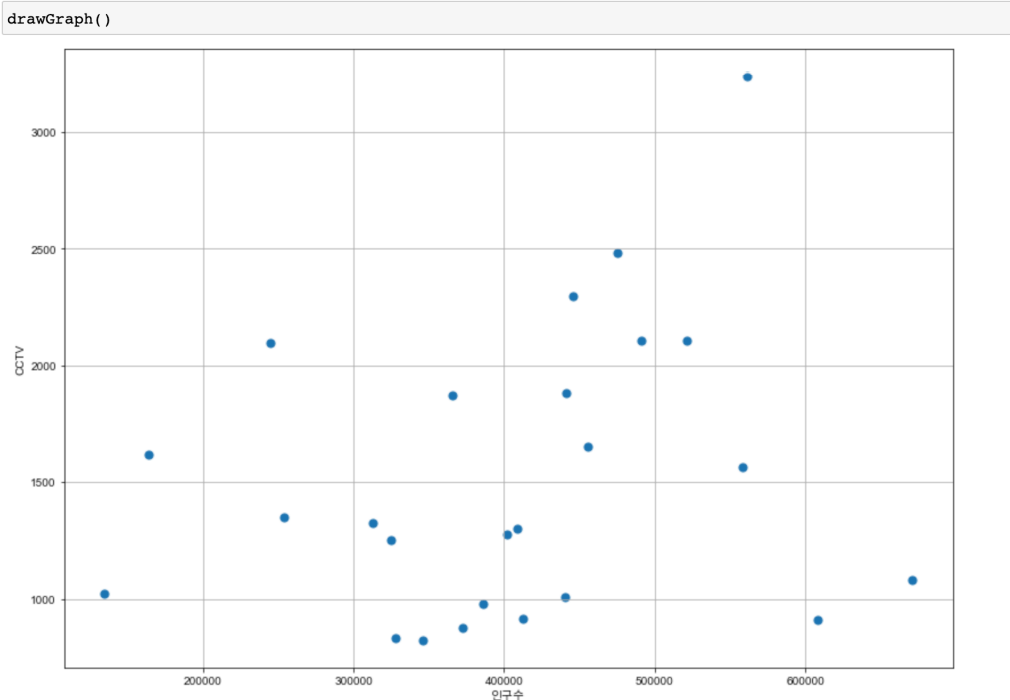
선형회귀(Linear Regression) Trend 파악
Numpy를 이용한 1차 직선 만들기
- np.polyfit : 직선을 구성하기 위한 계수 계산
- np.poly1d : polyfit으로 찾은 계수로 python에서 사용할 함수로 만들어 줌


- plyfit에서 찾은 계수를 넣어 함수 완성
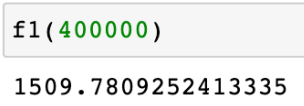
인구 400000인 구에서 서울시의 전체 경향에 맞는 적당한 CCTV 수?

- 경향선을 그리기 위해 X 데이터 생성
- np.linspace(a, b ,n) : a부터 b까지 n개의 등간격 데이터 생성

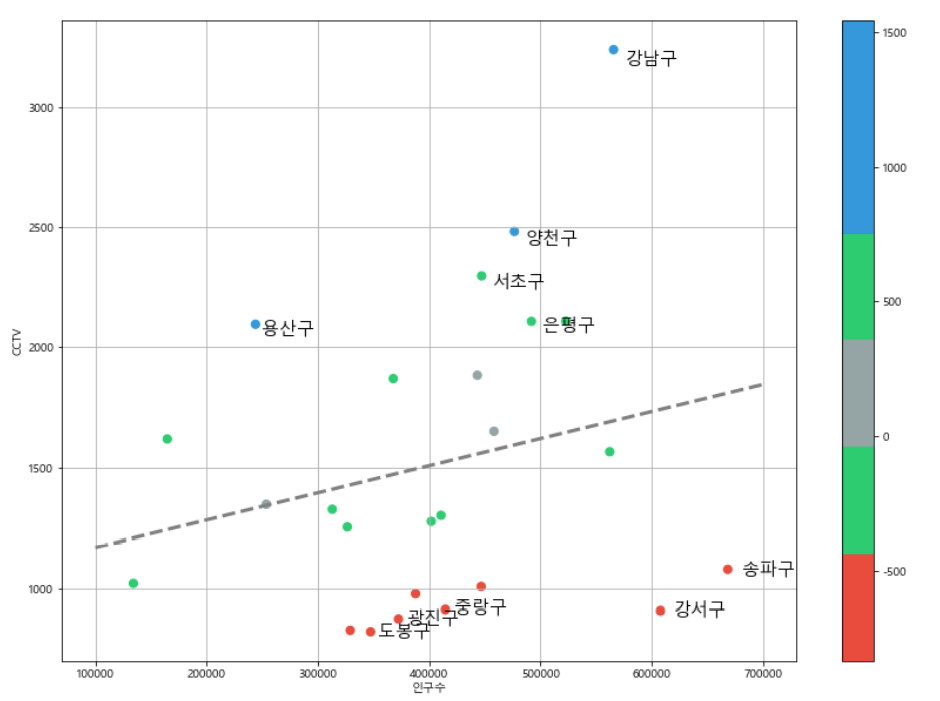
경향에서 벗어난 데이터 강조
그래프 다듬기
data_result[‘오차’] = data_result[‘소계’]-f1(data_result[‘인구수])
- 경향(trend)과의 오차 만들기
- 경향은 f1 함수에 해당 인구를 입력 : f1(data_result[‘인구수’])
- 현재값 : data_result[‘소계’]

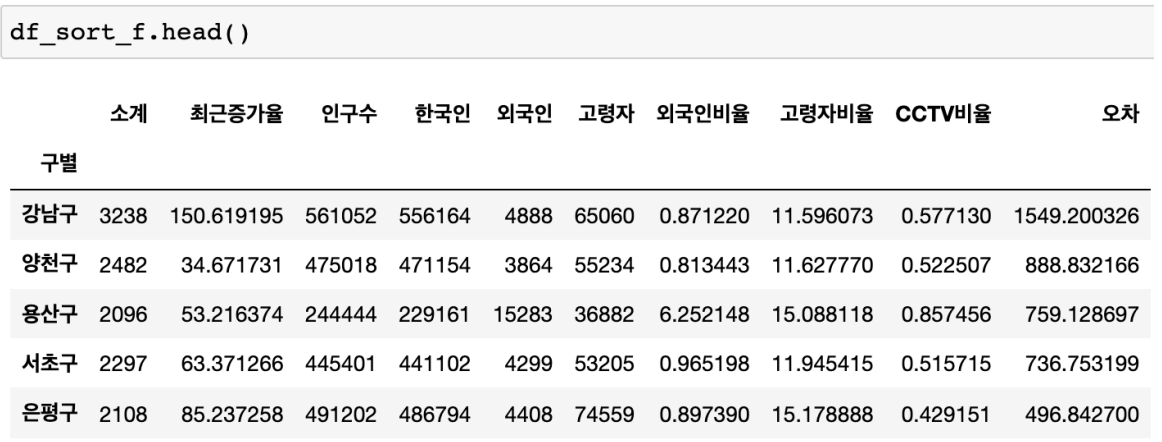
경향 대비 CCTV를 많이 가진 구
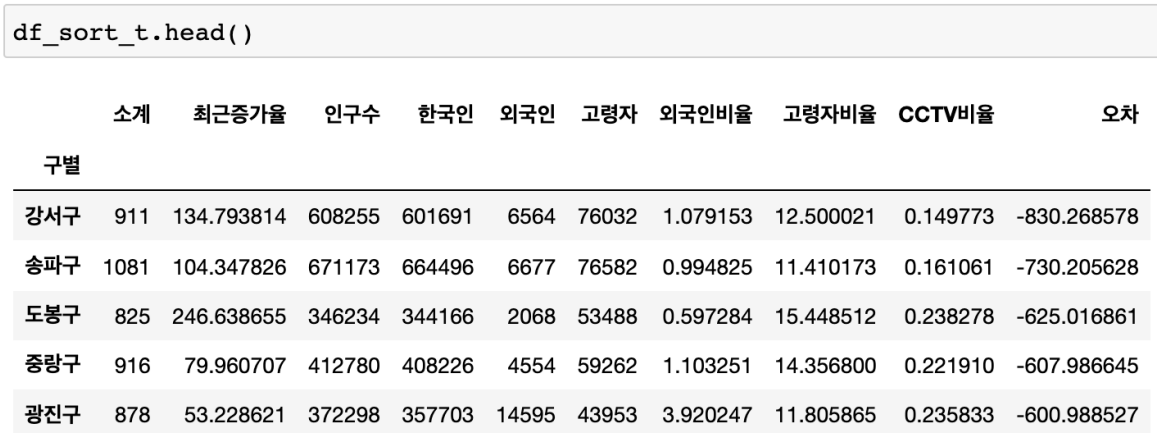
경향 대비 CCTV를 적게 가진 구
강조하고 싶은 데이터 시각화



- s : 마커의 크기
- c : color 세팅에 방금 계산한 경향과의 오차 적용
- cmap : 사용자 정의한 맵 적용

- 오차가 큰 데이터 아래 위로 5개만 마커 옆에 구 이름 명시

- text : 그래프에 글자를 그리는 명령
- plt.text(x, y, text, 설정)
- x, y 데이터에 1.02, 0.98을 곱해 구 이름이 마커에 겹치지 않도록 설정
데이터 저장

출처
서울시 자치구 년도별 CCTV 설치 현황, https://data.seoul.go.kr/dataList/OA-2734/F/1/datasetView.do 서울시 주민등록인구 통계, https://data.seoul.go.kr/dataList/419/S/2/datasetView.do