Project 6 - 주유소 가격 비교
Selenium Basic
- https://www.selenium.dev/documentation/
1. 셀레니움 설치
- 윈도우, mac(intel)
- conda install selenium
- mac(m1)
- pip install selenium
2. selenium webdriver 사용하기
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome(executable_path="../drive/chromedriver.exe")
driver.get("https://pinkwink.kr")
driver.quit() # 드라이버 종료
# 화면 최대 크기 설정
driver.maximize_window()
# 화면 최소 크기 설정
driver.minimize_window()
# 화면 크기 설정
driver.set_window_size(600, 600)
# 새로 고침
driver.refresh()
# 뒤로 가기
driver.back()
# 앞으로 가기
driver.forward()
#클릭
first_content = driver.find_element(By.CSS_SELECTOR, '#content > div.cover-masonry > div > ul > li:nth-child(1)')
first_content.click()
# 새로운 탭 생성
driver.execute_script('window.open("https://www.naver.com")')
# 탭 이동
driver.switch_to.window(driver.window_handles[0])
# 탭 닫기
driver.close()
3. 화면 스크롤
# 스크롤 가능한 높이(길이)
# 자바스크립트 코드 실행
driver.execute_script('return document.body.scrollHeight')
# 화면 스크롤 하단 이동
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 현재 보이는 화면 스크린샷 저장
driver.save_screenshot("./last_height.png")
# 화면 스크롤 상단 이동
driver.execute_script("window.scrollTo(0, 0);")
# 특정 태그 지점까지 스크롤 이동
from selenium.webdriver import ActionChains
some_tag = driver.find_element(By.CSS_SELECTOR, "#content > div:nth-child(2) > div > ul > li:nth-child(1)")
action = ActionChains(driver)
action.move_to_element(some_tag).perform()
4. 검색어 입력
CSS_SELECTOR
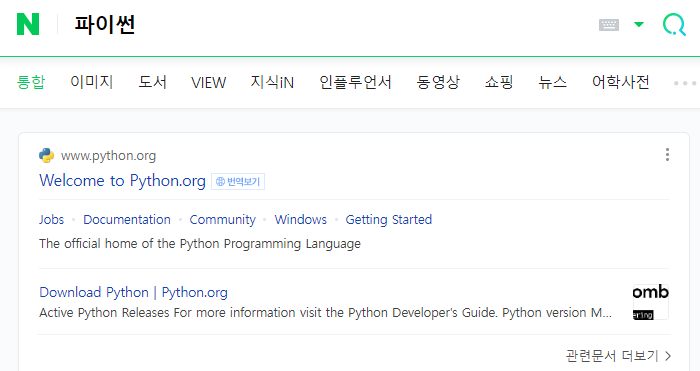
driver = webdriver.Chrome('../drive/chromedriver.exe')
driver.get("https://www.naver.com")
keyword = driver.find_element(By.CSS_SELECTOR, "#query")
keyword.clear()
keyword.send_keys("파이썬")

search_btn = driver.find_element(By.CSS_SELECTOR, "#search_btn")
search_btn.click()
XPATH
'//': 최상위
'*': 자손 태그
'/': 자식 태그
'div[1]': div 중에서 1번째 태그
''
ex) //*[@id="main_pack"]/section[2]/div/div[2]/panel-list/div/ul/li[1]/div/div/a
driver = webdriver.Chrome('../drive/chromedriver.exe')
driver.get('https://pinkwink.kr')
# 1. 돋보기 버튼을 선택
from selenium.webdriver import ActionChains
search_tag = driver.find_element(By.CSS_SELECTOR, '.search')
action = ActionChains(driver)
action.click(search_tag)
action.perform()

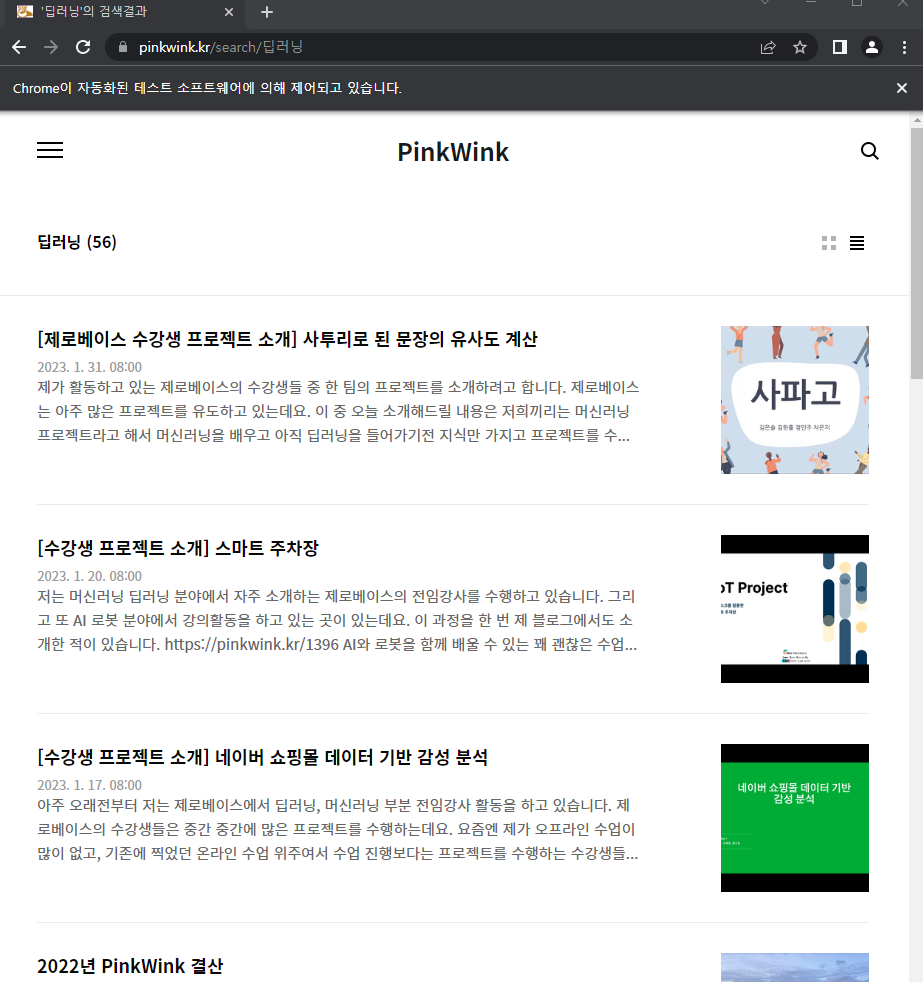
# 2. 검색어를 입력
driver.find_element(By.CSS_SELECTOR, '#header > div.search.on > input[type=text]').send_keys('딥러닝')

# 3. 검색 버튼 클릭
driver.find_element(By.CSS_SELECTOR, '#header > div.search > button').click()
5. selenium + beautifulsoup
# 현재 화면의 html 코드 가져오기
driver.page_source
=>
<html lang="ko"><head>\n \n \n <!-- BusinessLicenseInfo - START -->\n \n <link
.
.
.
from bs4 import BeautifulSoup
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
soup.select('.post-item')
=>
[<div class="post-item">
<a href="/1410">
<span class="thum">
<img alt="" src="//i1.daumcdn.net/thumb/C264x200/?fname=https://blog.kakaocdn.net/dn/cn2qfp/btrW2tEffvS/m98SKBp0PBaA93pASI4Cl1/im
.
.
.
시 올라올때 코란도 2인슨 벤 화물칸과 조수석에 짐을 pinkwink.kr 여러가지 상황이 있겠지만, 핑크랩이 선호하는 상황은 조금 특정지어져 있습니다. 기업은 아직 본격적으로 팀을 빌딩하지 못했거나 혹은 가능성을 먼저 보고 싶..</span>
</a>
</div>]
contents[2]
=>
<div class="post-item">
<a href="/1407">
<span class="thum">
<img alt="" src="//i1.daumcdn.net/thumb/C264x200/?fname=https://blog.kakaocdn.net/dn/wpuRJ/btrWismzvEK/d5xmwkQwdKvMew1fGM7KXk/img.png"/>
</span>
<span class="title">[수강생 프로젝트 소개] 네이버 쇼핑몰 데이터 기반 감성 분석</span>
<span class="date">2023. 1. 17. 08:00</span>
<span class="excerpt">...이런 저런 이..</span>
</a>
</div>
정말 셀프 주유소가 저렴할까?
1. 데이터 확보하기 위한 작업
- https://www.opinet.co.kr/searRqSelect.do
- 사이트 구조 확인
- 목표 데이터
- 브랜드
- 가격
- 셀프 주유 여부
- 위치
2. 셀레니움으로 접근
requirements
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
페이지 접근
# 페이지 접근
url = "https://www.opinet.co.kr/searRgSelect.do"
driver = webdriver.Chrome("../drive/chromedriver.exe")
driver.get(url)
time.sleep(1)
driver.get(url)
지역: 시/도
sido_list_raw = driver.find_element(By.CSS_SELECTOR, "#SIDO_NM0")
sido_list_raw.text

sido_list = sido_list_raw.find_elements(By.CSS_SELECTOR, 'option')
len(sido_list), sido_list[17].text
=>
(18, '제주')
sido_list[1].get_attribute("value")
=>
'서울특별시'
# sido_names = []
# for option in sido_list:
# sido_names.append(option.get_attribute("value"))
sido_names = [option.get_attribute("value") for option in sido_list]
sido_names[:5]
=>
['', '서울특별시', '부산광역시', '대구광역시', '인천광역시']
sido_names = sido_names[1:]
sido_names
=>
['서울특별시',
'부산광역시',
'대구광역시',
.
.
.
'경상남도',
'제주특별자치도']
구
gu_list_raw = driver.find_element(By.ID, 'SIGUNGU_NM0') # 부모 태그
gu_list = gu_list_raw.find_elements(By.TAG_NAME, 'option') # 자식 태그
gu_names = [option.get_attribute("value") for option in gu_list]
gu_names = gu_names[1:]
gu_names[:5], len(gu_names)
=>
(['강남구', '강동구', '강북구', '강서구', '관악구'], 25)
엑셀 저장
from tqdm import tqdm_notebook
for gu in tqdm_notebook(gu_names):
element = driver.find_element(By.ID, 'SIGUNGU_NM0')
element.send_keys(gu)
time.sleep(1)
element_get_excel = driver.find_element(By.XPATH, ('//*[@id="glopopd_excel"]')).click()
time.sleep(1)
driver.close()
3. 데이터 정리
requirements
import pandas as pd
from glob import glob
파일 목록 한번에 가져오기
glob('../data/지역_*.xls')
=>
['../data\\지역_위치별(주유소) (1).xls',
'../data\\지역_위치별(주유소) (10).xls',
'../data\\지역_위치별(주유소) (11).xls',
.
.
.
'../data\\지역_위치별(주유소) (8).xls',
'../data\\지역_위치별(주유소) (9).xls',
'../data\\지역_위치별(주유소).xls']
# 파일명 저장
stations_files = glob('../data/지역_*.xls')
# 하나만 읽어보기
tmp = pd.read_excel(stations_files[0], header=2)
tmp.tail(2)
| 지역 | 상호 | 주소 | 상표 | 전화번호 | 셀프여부 | 고급휘발유 | 휘발유 | 경유 | 실내등유 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 12 | 서울특별시 | 천호현대주유소 | 서울 강동구 천중로 67 (천호동) | 현대오일뱅크 | 02-484-9323 | N | - | 1823 | 1924 | - |
| 13 | 서울특별시 | 광성주유소 | 서울 강동구 올림픽로 673 (천호동) | S-OIL | 02-470-5133 | N | - | 1978 | 2028 | 1900 |
</div></div></div>
concat
- 형식이 동일하고 연달아 붙이기만 하면 될 때
tmp_raw = []
for file_name in stations_files:
tmp = pd.read_excel(file_name, header=2)
tmp_raw.append(tmp)
stations_raw = pd.concat(tmp_raw)
stations_raw
| 지역 | 상호 | 주소 | 상표 | 전화번호 | 셀프여부 | 고급휘발유 | 휘발유 | 경유 | 실내등유 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 서울특별시 | 재건에너지 재정제2주유소 고속셀프지점 | 서울특별시 강동구 천호대로 1246 (둔촌제2동) | 현대오일뱅크 | 02-487-2030 | Y | - | 1569 | 1669 | - |
| 1 | 서울특별시 | 구천면주유소 | 서울 강동구 구천면로 357 (암사동) | 현대오일뱅크 | 02-441-0536 | N | - | 1584 | 1693 | - |
| 2 | 서울특별시 | (주)소모에너지 신월주유소 | 서울 강동구 양재대로 1323 (성내동) | GS칼텍스 | 02-6956-6674 | Y | 1836 | 1586 | 1698 | 1650 |
| 3 | 서울특별시 | 대성석유(주)길동주유소 | 서울 강동구 천호대로 1168 | GS칼텍스 | 02-474-7222 | N | 1845 | 1596 | 1728 | 1600 |
| 4 | 서울특별시 | (주)삼표에너지 고덕주유소 | 서울 강동구 고덕로 39 (암사동) | GS칼텍스 | 02-441-3327 | Y | 1845 | 1625 | 1745 | 1615 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 28 | 서울특별시 | 대청주유소 | 서울 강남구 개포로 654 (일원동) | SK에너지 | 02-445-5500 | N | 2486 | 2246 | 2236 | 1836 |
| 29 | 서울특별시 | 갤러리아주유소 | 서울 강남구 압구정로 426 | SK에너지 | 02-540-4965 | N | 2488 | 2290 | 2349 | 1840 |
| 30 | 서울특별시 | SK논현주유소 | 서울 강남구 논현로 747 (논현동) | SK에너지 | 02-511-0955 | N | 2495 | 2290 | 2360 | 1835 |
| 31 | 서울특별시 | (주)새서울네트웍스 제이제이주유소 | 서울 강남구 언주로 716 | 현대오일뱅크 | 02-518-5631 | N | 2548 | 2298 | 2387 | - |
| 32 | 서울특별시 | (주)만정에너지 삼보주유소 | 서울 강남구 봉은사로 433 (삼성동) | GS칼텍스 | 02-518-5141 | N | 2818 | 2578 | 2570 | 1850 |
stations_raw.info()
=>
<class 'pandas.core.frame.DataFrame'>
Int64Index: 443 entries, 0 to 32
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 지역 443 non-null object
1 상호 443 non-null object
2 주소 443 non-null object
3 상표 443 non-null object
4 전화번호 443 non-null object
5 셀프여부 443 non-null object
6 고급휘발유 443 non-null object
7 휘발유 443 non-null object
8 경유 443 non-null object
9 실내등유 443 non-null object
dtypes: object(10)
memory usage: 38.1+ KB
stations_raw.columns
=>
Index(['지역', '상호', '주소', '상표', '전화번호', '셀프여부', '고급휘발유', '휘발유', '경유', '실내등유'], dtype='object')
stations = pd.DataFrame({
"상호": stations_raw["상호"],
"주소": stations_raw["주소"],
"가격": stations_raw["휘발유"],
"셀프": stations_raw["셀프여부"],
"상표": stations_raw["상표"]
})
stations.tail()
| 상호 | 주소 | 가격 | 셀프 | 상표 | |
|---|---|---|---|---|---|
| 28 | 대청주유소 | 서울 강남구 개포로 654 (일원동) | 2246 | N | SK에너지 |
| 29 | 갤러리아주유소 | 서울 강남구 압구정로 426 | 2290 | N | SK에너지 |
| 30 | SK논현주유소 | 서울 강남구 논현로 747 (논현동) | 2290 | N | SK에너지 |
| 31 | (주)새서울네트웍스 제이제이주유소 | 서울 강남구 언주로 716 | 2298 | N | 현대오일뱅크 |
| 32 | (주)만정에너지 삼보주유소 | 서울 강남구 봉은사로 433 (삼성동) | 2578 | N | GS칼텍스 |
for eachAddress in stations["주소"]:
print(eachAddress.split()[1])
=>
강동구
강동구
강동구
.
.
.
강남구
강남구
강남구
stations["구"] = [eachAddress.split()[1] for eachAddress in stations["주소"]]
stations
| 상호 | 주소 | 가격 | 셀프 | 상표 | 구 | |
|---|---|---|---|---|---|---|
| 0 | 재건에너지 재정제2주유소 고속셀프지점 | 서울특별시 강동구 천호대로 1246 (둔촌제2동) | 1569 | Y | 현대오일뱅크 | 강동구 |
| 1 | 구천면주유소 | 서울 강동구 구천면로 357 (암사동) | 1584 | N | 현대오일뱅크 | 강동구 |
| 2 | (주)소모에너지 신월주유소 | 서울 강동구 양재대로 1323 (성내동) | 1586 | Y | GS칼텍스 | 강동구 |
| 3 | 대성석유(주)길동주유소 | 서울 강동구 천호대로 1168 | 1596 | N | GS칼텍스 | 강동구 |
| 4 | (주)삼표에너지 고덕주유소 | 서울 강동구 고덕로 39 (암사동) | 1625 | Y | GS칼텍스 | 강동구 |
| ... | ... | ... | ... | ... | ... | ... |
| 28 | 대청주유소 | 서울 강남구 개포로 654 (일원동) | 2246 | N | SK에너지 | 강남구 |
| 29 | 갤러리아주유소 | 서울 강남구 압구정로 426 | 2290 | N | SK에너지 | 강남구 |
| 30 | SK논현주유소 | 서울 강남구 논현로 747 (논현동) | 2290 | N | SK에너지 | 강남구 |
| 31 | (주)새서울네트웍스 제이제이주유소 | 서울 강남구 언주로 716 | 2298 | N | 현대오일뱅크 | 강남구 |
| 32 | (주)만정에너지 삼보주유소 | 서울 강남구 봉은사로 433 (삼성동) | 2578 | N | GS칼텍스 | 강남구 |
stations["구"].unique(), len(stations["구"].unique())
=>
(array(['강동구', '동대문구', '동작구', '마포구', '서대문구', '서초구', '성동구', '성북구', '송파구',
'양천구', '영등포구', '강북구', '용산구', '은평구', '종로구', '중구', '중랑구', '강서구',
'관악구', '광진구', '구로구', '금천구', '노원구', '도봉구', '강남구'], dtype=object),
25)
가격 데이터형 변환 object -> float
stations["가격"] = stations["가격"].astype("float")
=>
ValueError: could not convert string to float: '-'
가격 정보 있는 주유소만 사용
# 가격 정보 없는 주유소
stations[stations["가격"] == "-"]
| 상호 | 주소 | 가격 | 셀프 | 상표 | 구 | |
|---|---|---|---|---|---|---|
| 15 | 제이제이에너지 | 서울 은평구 응암로 163 | - | Y | SK에너지 | 은평구 |
stations = stations[stations["가격"] != "-"]
stations.tail()
| 상호 | 주소 | 가격 | 셀프 | 상표 | 구 | |
|---|---|---|---|---|---|---|
| 28 | 대청주유소 | 서울 강남구 개포로 654 (일원동) | 2246 | N | SK에너지 | 강남구 |
| 29 | 갤러리아주유소 | 서울 강남구 압구정로 426 | 2290 | N | SK에너지 | 강남구 |
| 30 | SK논현주유소 | 서울 강남구 논현로 747 (논현동) | 2290 | N | SK에너지 | 강남구 |
| 31 | (주)새서울네트웍스 제이제이주유소 | 서울 강남구 언주로 716 | 2298 | N | 현대오일뱅크 | 강남구 |
| 32 | (주)만정에너지 삼보주유소 | 서울 강남구 봉은사로 433 (삼성동) | 2578 | N | GS칼텍스 | 강남구 |
다시 가격 데이터형 변환
stations["가격"] = stations["가격"].astype("float")
stations.info()
=>
<class 'pandas.core.frame.DataFrame'>
Int64Index: 442 entries, 0 to 32
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 상호 442 non-null object
1 주소 442 non-null object
2 가격 442 non-null float64
3 셀프 442 non-null object
4 상표 442 non-null object
5 구 442 non-null object
dtypes: float64(1), object(5)
memory usage: 24.2+ KB
stations
| 상호 | 주소 | 가격 | 셀프 | 상표 | 구 | |
|---|---|---|---|---|---|---|
| 0 | 재건에너지 재정제2주유소 고속셀프지점 | 서울특별시 강동구 천호대로 1246 (둔촌제2동) | 1569.0 | Y | 현대오일뱅크 | 강동구 |
| 1 | 구천면주유소 | 서울 강동구 구천면로 357 (암사동) | 1584.0 | N | 현대오일뱅크 | 강동구 |
| 2 | (주)소모에너지 신월주유소 | 서울 강동구 양재대로 1323 (성내동) | 1586.0 | Y | GS칼텍스 | 강동구 |
| 3 | 대성석유(주)길동주유소 | 서울 강동구 천호대로 1168 | 1596.0 | N | GS칼텍스 | 강동구 |
| 4 | (주)삼표에너지 고덕주유소 | 서울 강동구 고덕로 39 (암사동) | 1625.0 | Y | GS칼텍스 | 강동구 |
| ... | ... | ... | ... | ... | ... | ... |
| 28 | 대청주유소 | 서울 강남구 개포로 654 (일원동) | 2246.0 | N | SK에너지 | 강남구 |
| 29 | 갤러리아주유소 | 서울 강남구 압구정로 426 | 2290.0 | N | SK에너지 | 강남구 |
| 30 | SK논현주유소 | 서울 강남구 논현로 747 (논현동) | 2290.0 | N | SK에너지 | 강남구 |
| 31 | (주)새서울네트웍스 제이제이주유소 | 서울 강남구 언주로 716 | 2298.0 | N | 현대오일뱅크 | 강남구 |
| 32 | (주)만정에너지 삼보주유소 | 서울 강남구 봉은사로 433 (삼성동) | 2578.0 | N | GS칼텍스 | 강남구 |
인덱스 재정렬
stations.reset_index(inplace=True)
stations.tail()
| index | 상호 | 주소 | 가격 | 셀프 | 상표 | 구 | |
|---|---|---|---|---|---|---|---|
| 437 | 28 | 대청주유소 | 서울 강남구 개포로 654 (일원동) | 2246.0 | N | SK에너지 | 강남구 |
| 438 | 29 | 갤러리아주유소 | 서울 강남구 압구정로 426 | 2290.0 | N | SK에너지 | 강남구 |
| 439 | 30 | SK논현주유소 | 서울 강남구 논현로 747 (논현동) | 2290.0 | N | SK에너지 | 강남구 |
| 440 | 31 | (주)새서울네트웍스 제이제이주유소 | 서울 강남구 언주로 716 | 2298.0 | N | 현대오일뱅크 | 강남구 |
| 441 | 32 | (주)만정에너지 삼보주유소 | 서울 강남구 봉은사로 433 (삼성동) | 2578.0 | N | GS칼텍스 | 강남구 |
del stations["index"]
stations.tail()
| 상호 | 주소 | 가격 | 셀프 | 상표 | 구 | |
|---|---|---|---|---|---|---|
| 437 | 대청주유소 | 서울 강남구 개포로 654 (일원동) | 2246.0 | N | SK에너지 | 강남구 |
| 438 | 갤러리아주유소 | 서울 강남구 압구정로 426 | 2290.0 | N | SK에너지 | 강남구 |
| 439 | SK논현주유소 | 서울 강남구 논현로 747 (논현동) | 2290.0 | N | SK에너지 | 강남구 |
| 440 | (주)새서울네트웍스 제이제이주유소 | 서울 강남구 언주로 716 | 2298.0 | N | 현대오일뱅크 | 강남구 |
| 441 | (주)만정에너지 삼보주유소 | 서울 강남구 봉은사로 433 (삼성동) | 2578.0 | N | GS칼텍스 | 강남구 |
4. 주유 가격 정보 시각화
import matplotlib.pyplot as plt
import seaborn as sns
import platform
from matplotlib import font_manager, rc
get_ipython().run_line_magic("matplotlib", "inline")
# %matplotlib inline
path = "C:/Windows/Fonts/malgun.ttf"
if platform.system() == "Darwin":
rc("font", family="Arial Unicode MS")
elif platform.system() == "Windows":
font_name = font_manager.FontProperties(fname=path).get_name()
rc("font", family=font_name)
else:
print("Unknown system. sorry~")
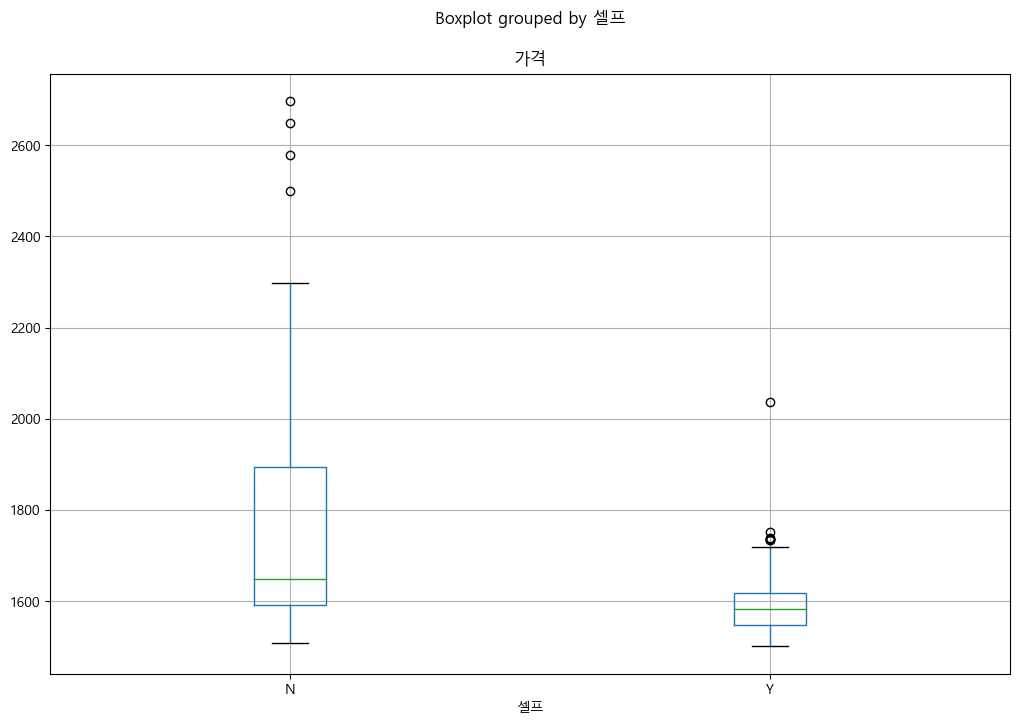
boxplot(feat. pandas)
stations.boxplot(column="가격", by="셀프", figsize=(12, 8));
boxplot(feat. seaborn)
plt.figure(figsize=(12, 8))
sns.boxplot(x="셀프", y="가격", data=stations, palette="Set3")
plt.grid(True)
plt.show()
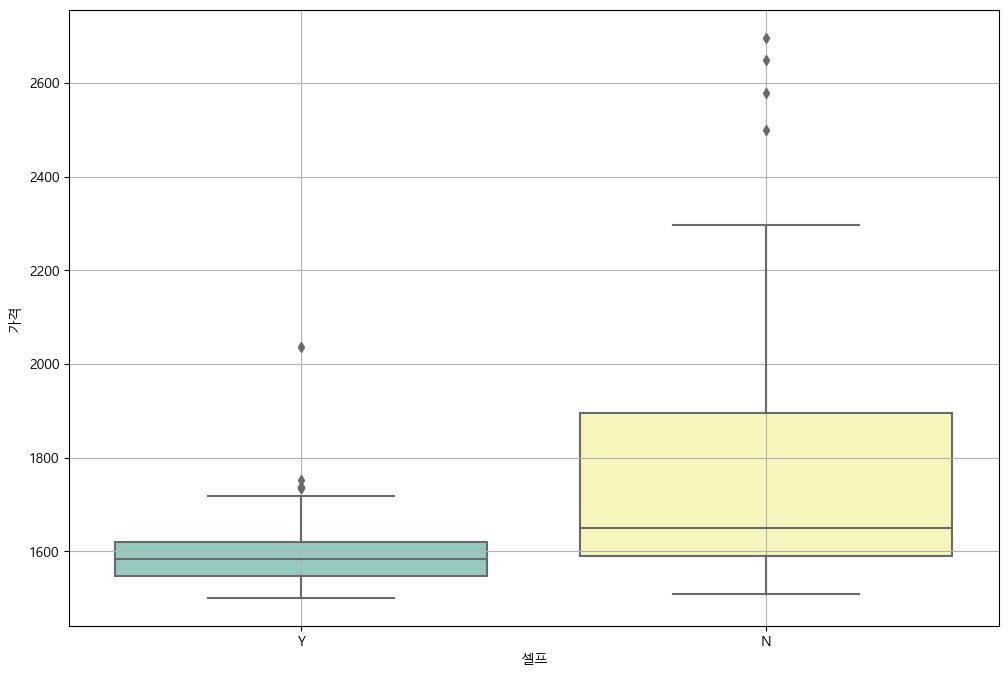
boxplot(feat. seaborn)
plt.figure(figsize=(12, 8))
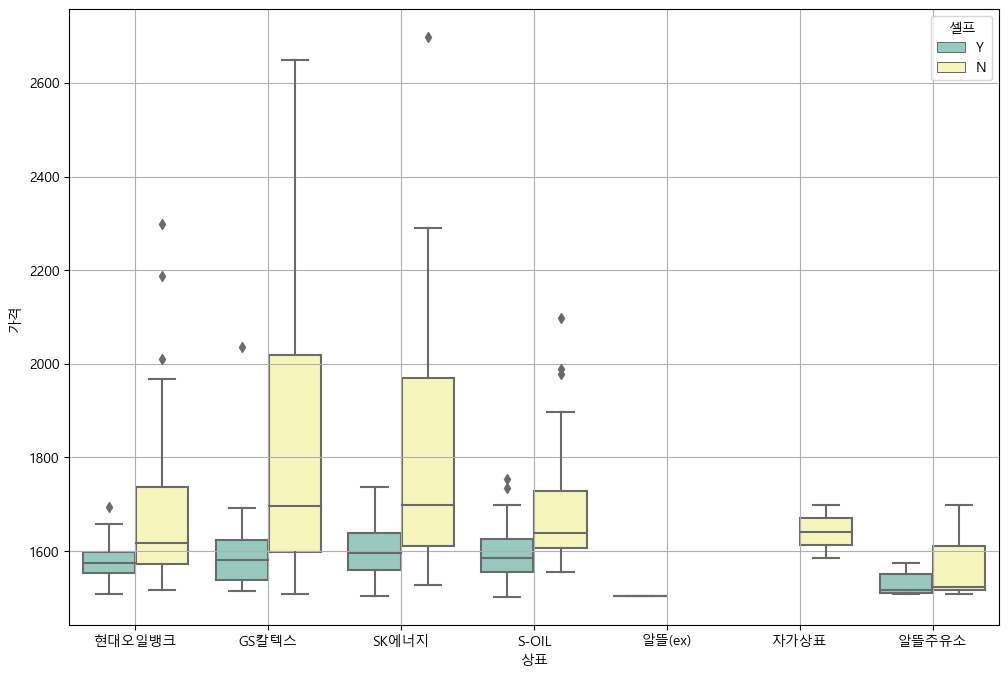
sns.boxplot(x="상표", y="가격", hue="셀프", data=stations, palette="Set3")
plt.grid(True)
plt.show()
import json
import folium
import warnings
warnings.simplefilter(action="ignore", category=FutureWarning)
가장 비싼 주유소 10개
stations.sort_values(by="가격", ascending=False).head(10)
| 상호 | 주소 | 가격 | 셀프 | 상표 | 구 | |
|---|---|---|---|---|---|---|
| 273 | 서남주유소 | 서울 중구 통일로 30 | 2697.0 | N | SK에너지 | 중구 |
| 240 | 서계주유소 | 서울 용산구 청파로 367 (청파동) | 2649.0 | N | GS칼텍스 | 용산구 |
| 441 | (주)만정에너지 삼보주유소 | 서울 강남구 봉은사로 433 (삼성동) | 2578.0 | N | GS칼텍스 | 강남구 |
| 272 | 필동주유소 | 서울 중구 퇴계로 196 (필동2가) | 2499.0 | N | GS칼텍스 | 중구 |
| 440 | (주)새서울네트웍스 제이제이주유소 | 서울 강남구 언주로 716 | 2298.0 | N | 현대오일뱅크 | 강남구 |
| 239 | 한석주유소 | 서울 용산구 이촌로 164 | 2290.0 | N | SK에너지 | 용산구 |
| 438 | 갤러리아주유소 | 서울 강남구 압구정로 426 | 2290.0 | N | SK에너지 | 강남구 |
| 439 | SK논현주유소 | 서울 강남구 논현로 747 (논현동) | 2290.0 | N | SK에너지 | 강남구 |
| 437 | 대청주유소 | 서울 강남구 개포로 654 (일원동) | 2246.0 | N | SK에너지 | 강남구 |
| 238 | 에너비스 | 서울 용산구 한남대로 82 (한남동) | 2217.0 | N | SK에너지 | 용산구 |
가장 싼 주유소 10개
stations.sort_values(by="가격").head(10)
| 상호 | 주소 | 가격 | 셀프 | 상표 | 구 | |
|---|---|---|---|---|---|---|
| 52 | 구도일주유소 두꺼비 | 서울 서대문구 성산로 312 | 1501.0 | Y | S-OIL | 서대문구 |
| 67 | 만남의광장주유소 | 서울 서초구 양재대로12길 73-71 | 1504.0 | Y | 알뜰(ex) | 서초구 |
| 241 | 타이거주유소 | 서울 은평구 수색로 188 (증산동) | 1504.0 | Y | SK에너지 | 은평구 |
| 167 | 플라트(주)서호주유소 | 서울 양천구 남부순환로 317 | 1508.0 | N | GS칼텍스 | 양천구 |
| 287 | 이케이에너지(주) 강서주유소 | 서울 강서구 화곡로 273 (화곡동) | 1508.0 | Y | 현대오일뱅크 | 강서구 |
| 288 | 화곡역주유소 | 서울 강서구 강서로 154 (화곡동) | 1508.0 | Y | 알뜰주유소 | 강서구 |
| 289 | 뉴신정주유소 | 서울 강서구 곰달래로 207 (화곡동) | 1508.0 | N | 알뜰주유소 | 강서구 |
| 166 | 현대주유소 | 서울 양천구 남부순환로 372 (신월동) | 1508.0 | Y | S-OIL | 양천구 |
| 168 | 양천구주유소 | 서울 양천구 국회대로 275 (목동) | 1510.0 | Y | 알뜰주유소 | 양천구 |
| 290 | 목화주유소 | 서울 강서구 국회대로 251 (화곡동) | 1510.0 | Y | 알뜰주유소 | 강서구 |
import numpy as np
gu_data = pd.pivot_table(data=stations, index="구", values="가격", aggfunc=np.mean)
gu_data.head()
| 가격 | |
|---|---|
| 구 | |
| 강남구 | 1884.454545 |
| 강동구 | 1669.642857 |
| 강북구 | 1546.583333 |
| 강서구 | 1588.181818 |
| 관악구 | 1642.214286 |
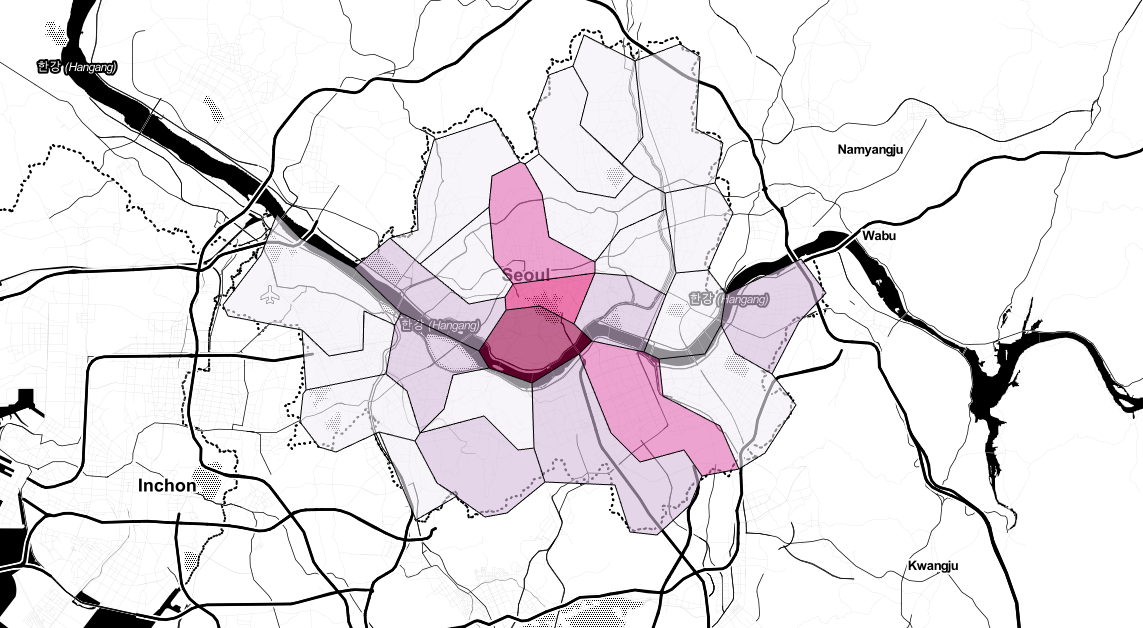
지도 시각화
geo_path = "../data/02. skorea_municipalities_geo_simple.json"
geo_str = json.load(open(geo_path, encoding="utf-8"))
my_map = folium.Map(location=[37.5502, 126.982], zoom_start=10.5, tiles="stamen toner")
my_map.choropleth(
geo_data=geo_str,
data=gu_data,
columns=[gu_data.index, "가격"],
key_on="feature.id",
fill_color="PuRd"
)
my_map